# 一、脚本管理
数据加工工具集包含如下功能:
# 1、编译器
定制Sql/Python
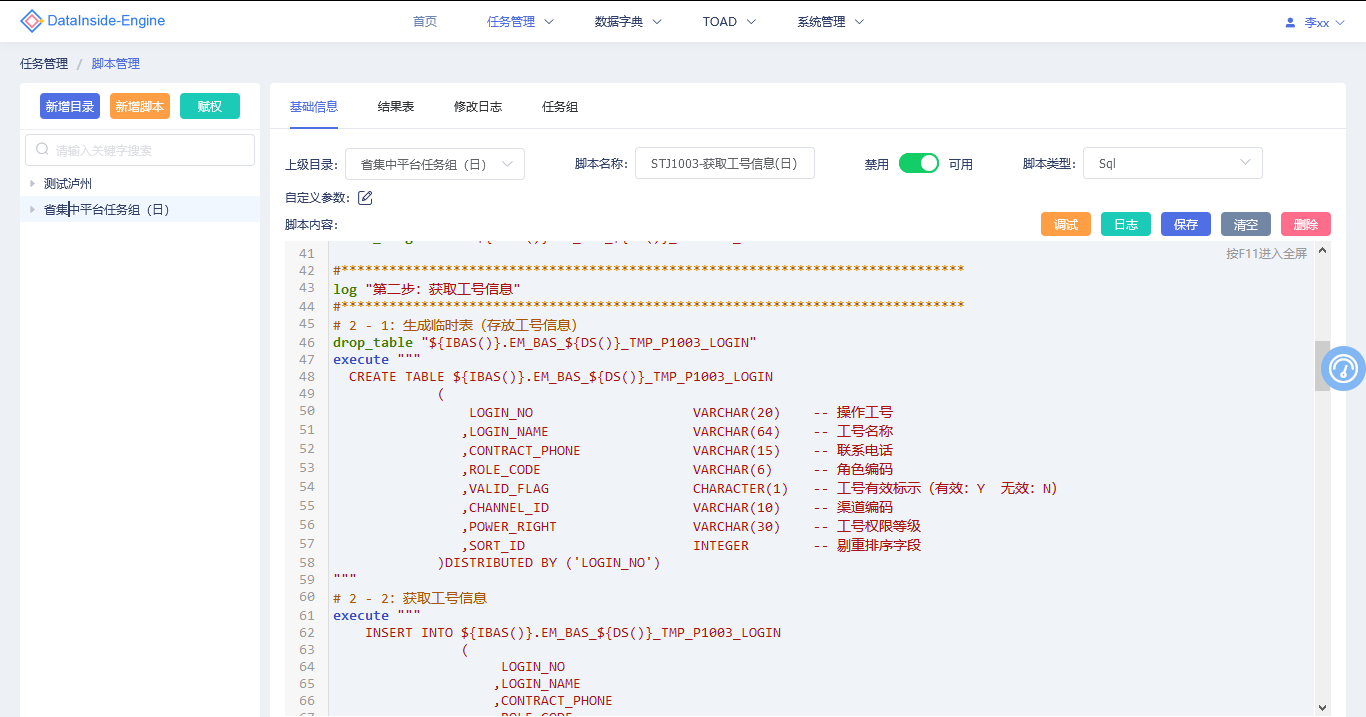
拥有定制的Sql、Python编译器,定制规范的脚本格式、脚本语法、脚本参数,让复杂的脚本编辑规范化简单化。
原生Sql/Shell
后续支持原生Sql、Shell的编译,可直接在编译器编辑调试原生Sql、Shell,让习惯原生的用户也可使用DataInside Engine的编译器。
# 2、集成IDE环境
代码高亮
根据不同脚本代码关键字类别用不同的颜色和字体高亮显示,有助于编写结构化的语言,同时也能帮助开发者很快的找到程序中的错误。
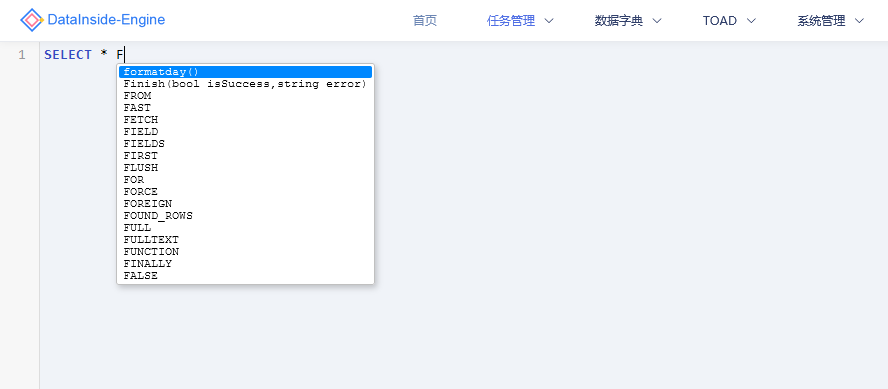
代码自动补全
支持代码补全,包括关键字补全、函数补全,后续扩展数据表补全、字段补全,让开发者代码编写更快捷准确。
代码格式化
支持代码自动格式化,避免了繁琐的手动调整代码格式,只需选中代码,然后点击格式化,就可一键按标准调整代码格式。
语法检查
后续支持脚本语法的检查,一键检查脚本语法,脚本函数,脚本参数等调用是否准确,方便开发者检查脚本错误。
在线调试
支持脚本在线调试,随时运行调试脚本,通过运行日志实时检测发现脚本编译中的语法错误或逻辑错误,待调试好完整的脚本再发布到系统。
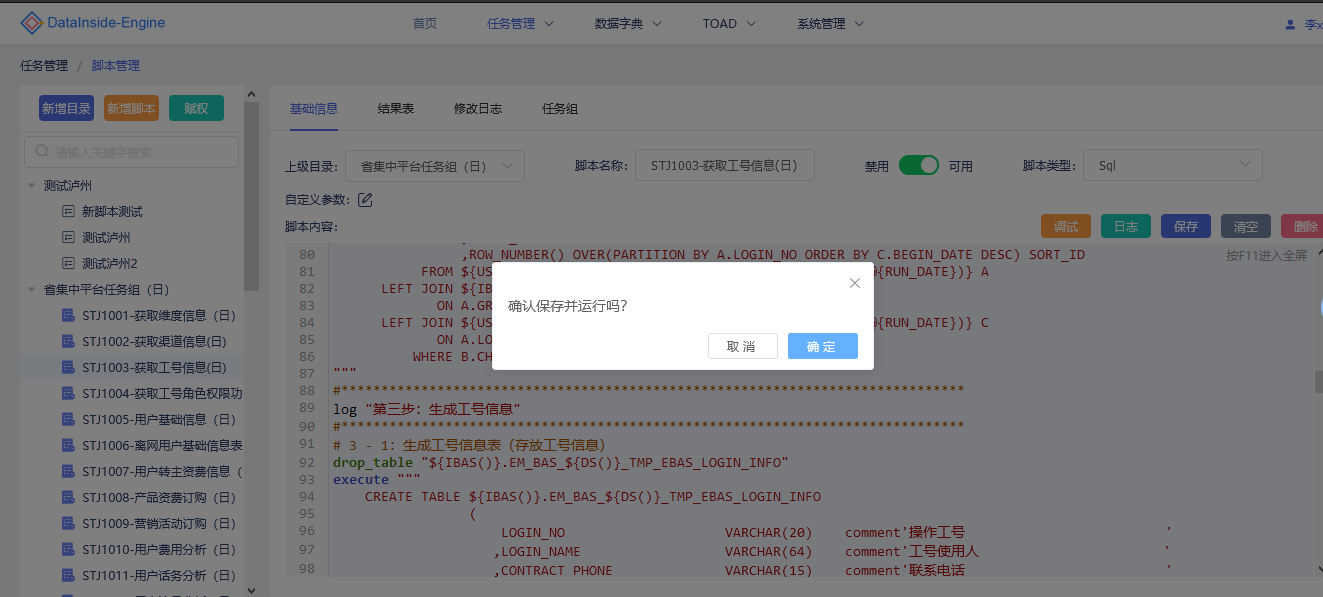
# 3、内置函数及自定义参数
# 内置函数
DataInside Engine内置33个辅助自定义函数,包括有日期函数,DDL函数,判断函数,循环函数,外导函数,日志打印函数,源表检测函数,通过各种函数的应用,可以使复杂的脚本语法简单化,提高脚本的编写和执行效率。
日期函数
now()
用途:返回当前日期时间
示例:TABLE_NAME表结构为:
| A_COLUMN | B_COLUMN | TIME |
|---|---|---|
| DHSWA | CKDHU |
执行语句:
UPDATE TABLE_NAME SET TIME=('{now()}')
返回结果:
| A_COLUMN | B_COLUMN | TIME |
|---|---|---|
| DHSWA | CKDHU | 2020-12-03 11:05:19 |
today()
用途:返回当前日期
示例:TABLE_NAME表结构为:
| A_COLUMN | B_COLUMN | TODAY |
|---|---|---|
| DHSWA | CKDHU |
执行语句:
UPDATE TABLE_NAME SET TODAY=('{today()}')
返回结果:
| A_COLUMN | B_COLUMN | TODAY |
|---|---|---|
| DHSWA | CKDHU | 2020-10-28 |
yyyymmdd()
用途:返回日期年月日,数值前面补0,可在括号里加减偏移日期。
示例:当前日期为20201026,TABLE_NAME表结构为:
| YMD1 | YMD2 | YMD3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YMD1,YMD2,YMD3) VALUES ('{yyyymmdd()}', '{yyyymmdd(2)}', '{yyyymmdd(-2)}')
返回结果:
| YMD1 | YMD2 | YMD3 |
|---|---|---|
| 20201026 | 20201028 | 20201024 |
yyyy-mm-dd()
用途:返回日期年月日,数值前面补0,可在括号里加减偏移日期。
示例:当前日期为2020-10-26,TABLE_NAME表结构为:
| YMD1 | YMD2 | YMD3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YMD1,YMD2,YMD3) VALUES ('{yyyy_mm_dd()}', '{yyyy_mm_dd(2)}', '{yyyy_mm_dd(-2)}')
返回结果:
| YMD1 | YMD2 | YMD3 |
|---|---|---|
| 2020-10-26 | 2020-10-28 | 2020-10-24 |
dd()
用途:返回两位数日期号数,数值前面补0,可在括号里加减偏移号数
示例:当前日期为20201201,TABLE_NAME表结构为:
| DD1 | DD2 | DD3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(DD1,DD2,DD3) VALUES ('{dd()}', '{dd(2)}', '{dd(-2)}')
返回结果:
| DD1 | DD2 | DD3 |
|---|---|---|
| 01 | 03 | 29 |
day()
用途:返回日期号数,数值前面不补0,可在括号里加减偏移号数
示例:当前日期为20201201,TABLE_NAME表结构为:
| DD1 | DD2 | DD3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(DD1,DD2,DD3) VALUES ('{day()}', '{day(2)}', '{day(-2)}')
返回结果:
| DD1 | DD2 | DD3 |
|---|---|---|
| 1 | 3 | 29 |
mmdd()
用途:返回日期月日,数值前面补0,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| MMDD1 | MMDD2 | MMDD3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YMD1,YMD2,YMD3) VALUES ('{mmdd()}', '{mmdd(2)}', '{mmdd(-2)}')
返回结果:
| MMDD1 | MMDD2 | MMDD3 |
|---|---|---|
| 1201 | 1203 | 1129 |
mm_dd()
用途:返回日期月日,数值前面补0,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| MMDD1 | MMDD2 | MMDD3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YMD1,YMD2,YMD3) VALUES ('{mm_dd()}', '{mm_dd(2)}', '{mm_dd(-2)}')
返回结果:
| MMDD1 | MMDD2 | MMDD3 |
|---|---|---|
| 12-01 | 12-03 | 11-29 |
yyyymm()
用途:返回日期年月,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| YM1 | YM2 | YM3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YM1,YM2,YM3) VALUES ('{yyyymm()}', '{yyyymm(2)}', '{yyyymm(-2)}')
返回结果:
| YM1 | YM2 | YM3 |
|---|---|---|
| 202012 | 202102 | 202010 |
yyyy_mm()
用途:返回日期年月,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| YM1 | YM2 | YM3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YM1,YM2,YM3) VALUES ('{yyyy_mm()}', '{yyyy_mm(2)}', '{yyyy_mm(-2)}')
返回结果:
| YM1 | YM2 | YM3 |
|---|---|---|
| 2020-12 | 2021-02 | 2020-10 |
mm()
用途:返回日期月份,个位数前补0,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| MM1 | MM2 | MM3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(MM1,MM2,MM3) VALUES ('{mm()}', '{mm(2)}', '{mm(-2)}')
返回结果:
| MM1 | MM2 | MM3 |
|---|---|---|
| 01 | 03 | 11 |
month()
用途:返回日期月份,个位数前不补0,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| MM1 | MM2 | MM3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(MM1,MM2,MM3) VALUES ('{month()}', '{ month(2)}', '{ month(-2)}')
返回结果:
| MM1 | MM2 | MM3 |
|---|---|---|
| 1 | 3 | 11 |
year()
用途:返回日期年份,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| YEAR1 | YEAR2 | YEAR3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME(YEAR1,YEAR2,YEAR2) VALUES ('{year()}', '{year (2)}', '{year (-2)}')
返回结果:
| YEAR1 | YEAR2 | YEAR3 |
|---|---|---|
| 2020 | 2022 | 2018 |
lastmonthcurday()
用途:返回上月当天日期,若当天31号而上月不足31天,则返回上月最后一天日期,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| A_COLUMN | B_COLUMN | LASTCD |
|---|---|---|
| DHSWA | CKDHU |
执行语句:
UPDATE TABLE_NAME SET LASTCD=('{lastmonthcurday()}')
返回结果:
| A_COLUMN | B_COLUMN | LASTCD |
|---|---|---|
| DHSWA | CKDHU | 20201101 |
last_month_curday()
用途:返回上月当天日期,若当天31号而上月不足31天,则返回上月最后一天日期,可在括号里加减偏移日期。
示例:当前日期为20201201,TABLE_NAME表结构为:
| A_COLUMN | B_COLUMN | LASTCD |
|---|---|---|
| DHSWA | CKDHU |
执行语句:
UPDATE TABLE_NAME SET LASTCD=('{last_month_curday()}')
返回结果:
| A_COLUMN | B_COLUMN | LASTCD |
|---|---|---|
| DHSWA | CKDHU | 2020-11-03 |
fistday()
用途:返回某月第一天日期,数值前面补0,可在括号里加减偏移月份。
示例:当前日期为20201203,TABLE_NAME表结构为:
| FISTDAY1 | FISTDAY2 | FISTDAY3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME (FISTDAY1, FISTDAY2, FISTDAY3) VALUES ('{fistday()}', '{fistday(2)}', '{fistday(-2)}')
返回结果:
| FISTDAY1 | FISTDAY2 | FISTDAY3 |
|---|---|---|
| 20201201 | 20210201 | 20201001 |
fist_day()
用途:返回某月第一天日期,数值前面补0,可在括号里加减偏移月份。
示例:当前日期为20201203,TABLE_NAME表结构为:
| FISTDAY1 | FISTDAY2 | FISTDAY3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME (FISTDAY1, FISTDAY2, FISTDAY3) VALUES ('{fist_day()}', '{fist_day(2)}', '{fist_day(-2)}')
返回结果:
| FISTDAY1 | FISTDAY2 | FISTDAY3 |
|---|---|---|
| 2020-12-01 | 2021-02-01 | 2020-10-01 |
lastday()
用途:返回某月最后一天日期,数值前面补0,可在括号里加减偏移月份。
示例:当前日期为20201203,TABLE_NAME表结构为:
| LASTDAY1 | LASTDAY2 | LASTDAY3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME (LASTDAY1, LASTDAY2, LASTDAY3) VALUES ('{lastday()}', '{lastday(2)}', '{lastday(-2)}')
返回结果:
| LASTDAY1 | LASTDAY2 | LASTDAY3 |
|---|---|---|
| 20201231 | 20210228 | 20201031 |
last_day()
用途:返回某月最后一天日期,数值前面补0,可在括号里加减偏移月份。
示例:当前日期为20201203,TABLE_NAME表结构为:
| LASTDAY1 | LASTDAY2 | LASTDAY3 |
|---|---|---|
执行语句:
INSERT INTO TABLE_NAME (LASTDAY1, LASTDAY2, LASTDAY3) VALUES ('{last_day()}', '{last_day(2)}', '{last_day(-2)}')
返回结果:
| LASTDAY1 | LASTDAY2 | LASTDAY3 |
|---|---|---|
| 2020-12-31 | 2021-02-28 | 2020-10-31 |
SQLDML函数
drop_table()
用途:可删除单表或多表。
语法:drop_table("t1, t2")
示例:
drop_table("table_name1"); drop_table("table_name1,table_name2");
truncate_table()
用途:清空表数据,可清空单表或多表。
语法:truncate_table("t1, t2")
示例:
truncate_table("table_name1"); truncate_table("table_name1,table_name2");
create_table()
用途:根据源表格式创建新表。
语法:create_table(table_name, like_name)
table_name:原表表名
like_name:要创建的表表名
示例:根据table_name1创建table_name2
create_table("table_name2","table_name1");
table_exists()
用途:检查表是否存在。
示例:如果没有表TBALE_NAME则创建表,如果有表TBALE_NAME则插入数据。
If(table_exists("TBALE_NAME")){ execute (""" CREATE TABLE TBALE_NAME (A_COLUMN VARCHAR(100), B_COLUMN VARCHAR(100), C_COLUMN VARCHAR(100) """); }else{ execute (""" INSERT INTO TBALE_NAME ( A_COLUMN,B_COLUMN,C_COLUMN) VALUES('5','6','7') """); };
column_exists()
用途:检查列是否存在。
示例:如果表TBALE_NAME里没有D_COLUMN列,则增加列;如果有D_COLUMN列则更新列;
if (column_exists("D_COLUMN")){ execute (""" ALTER TABLE TBALE_NAME ADD D_COLUMN INT """); }else{ execute (""" UPDATE TBALE_NAME SET A_COLUMN=10 """); };
sql****查询函数
execute()
用途:执行sql无返回;
示例:更新表字段
execute (""" UPDATE TBALE_NAME SET A_COLUMN=10 """);
execute_obj()
用途:执行sql返回字符串;
示例:查询表行数
String s=execute_obj(""" select count(1) from TBALE_NAME """);
execute_data()
用途:执行sql返回数据集;
示例:查询表数据集
List<HashMap<String,String>> s=execute_obj(""" select * from TBALE_NAME """);
日志输出函数
log_into_db()
用途:写日志到数据库。
语法:log_into_db(message);
message:文本,日志内容;
示例:
| log_into_db("这是一段测试"); 返回:"这是一段测试" |
|---|
| log_into_db("{yyyymmdd()}"); 返回:”20201204” |
跨库转换函数
set_db_by_name()
用途:根据名称选择数据库,后续的脚本将在这个数据库下执行。
示例:
set_db_by_name("EM_CN")
sourceDb_to_targetDb()
用途:从一个数据库迁移表数据到另外一个数据库。
语法:data_gbasetogbase(from_db,sql, from_table_name, table_name)
from_db:源数据库名
sql:sql语句
from_table_name:源表名
table_name:目标表名
示例:
data_gbasetogbase("em_cn", "", "EM_BAS_LZ_LOGIN_INFO","EM_BAS_LZ_LOGIN_INFO"); data_gbasetogbase("em_cn", "select * from EM_BAS_LZ_LOGIN_INFO", "","EM_BAS_LZ_LOGIN_INFO" );
主机函数
getCpu()
用途:查询linux主机cpu内存使用情况。
语法:getCpu(user,password,ip);
user:用户名
password:密码
ip:主机ip
示例:查询主机ip
getCpu("root","root", "127.0.0.1");
企业微信对接接口函数
get_qw_to_db_multi()
用途:获取企业微信接口的数据集并存入指定表
语法:get_qw_to_db_multi(https,corpid,corpsecret,httpDataJsonObject,fieldsJsonObject,tableName);
https:请求的ip地址
corpid:企业id
corpsecret:接口Secret
httpDataJsonObject:接口参数json
fieldsJsonObject:接口返回的json对应的表字段
tableName:存入的表名称
示例:获取企业微信客户群列表
jsonObject = new JSONObject(); JSONPath.set(jsonObject,"status_filter",0); JSONPath.set(jsonObject,"owner_filter.userid_list[0]","abel"); JSONPath.set(jsonObject,"cursor","r9FqSqsI8fgNbHLHE5QoCP50UIg2cFQbfma3l2QsmwI"); JSONPath.set(jsonObject,"limit",10); jsonObject1 = new JSONObject(); JSONPath.set(jsonObject1,"group_chat_list[0].chat_id","chat_id"); JSONPath.set(jsonObject1,"group_chat_list[0].status","status"); JSONPath.set(jsonObject1,"next_cursor","next_cursor"); get_qw_to_db_multi("https://qyapi.weixin.qq.com/cgi-bin/externalcontact/groupchat/list","wwc2ec284b7ac1234432","qerfr3443r3f2-tqCYa1vHxg4tuQagBsK2cFM",jsonObject,jsonObject1,"group_chat_list");
get_qw_to_db()
用途:获取企业微信接口的单条数据并存入指定表
语法:get_qw_to_db(https,corpid,corpsecret,httpDataJsonObject,fieldsJsonObject,tableName);
https:请求的ip地址
corpid:企业id
corpsecret:接口Secret
httpDataJsonObject:接口参数json
fieldsJsonObject:接口返回的json对应的表字段
tableName:存入的表名称
示例:获取企业微信客户详情
jsonObject = new JSONObject(); jsonObject1 = new JSONObject(); JSONPath.set(jsonObject1,"external_contact.external_userid","external_userid"); JSONPath.set(jsonObject1,"external_contact.name","name"); JSONPath.set(jsonObject1,"external_contact.avatar","avatar"); JSONPath.set(jsonObject1,"external_contact.corp_name","corp_name"); JSONPath.set(jsonObject1,"external_contact.corp_full_name","corp_full_name"); JSONPath.set(jsonObject1,"external_contact.type","type"); JSONPath.set(jsonObject1,"external_contact.gender","gender"); JSONPath.set(jsonObject1,"external_contact.unionid","unionid"); JSONPath.set(jsonObject1,"external_contact.position","position"); JSONPath.set(jsonObject1,"external_contact.external_userid","external_userid"); get_qw_to_db("https://qyapi.weixin.qq.com/cgi-bin/externalcontact/get?external_userid=ZhangTong&cursor=NEXT_CURSOR","wwc2ec284b7ac97620","2mPKB4Mk5VrSZe9sedD-tqCYa1vHxg4tuQagBsK2cFM",jsonObject,jsonObject1,"externalcontact");
# 自定义参数
DataInside Engine可根据实际需求自定义脚本动态参数,包括全局参数和单脚本参数,动态参数的使用可标准化和规范化脚本。
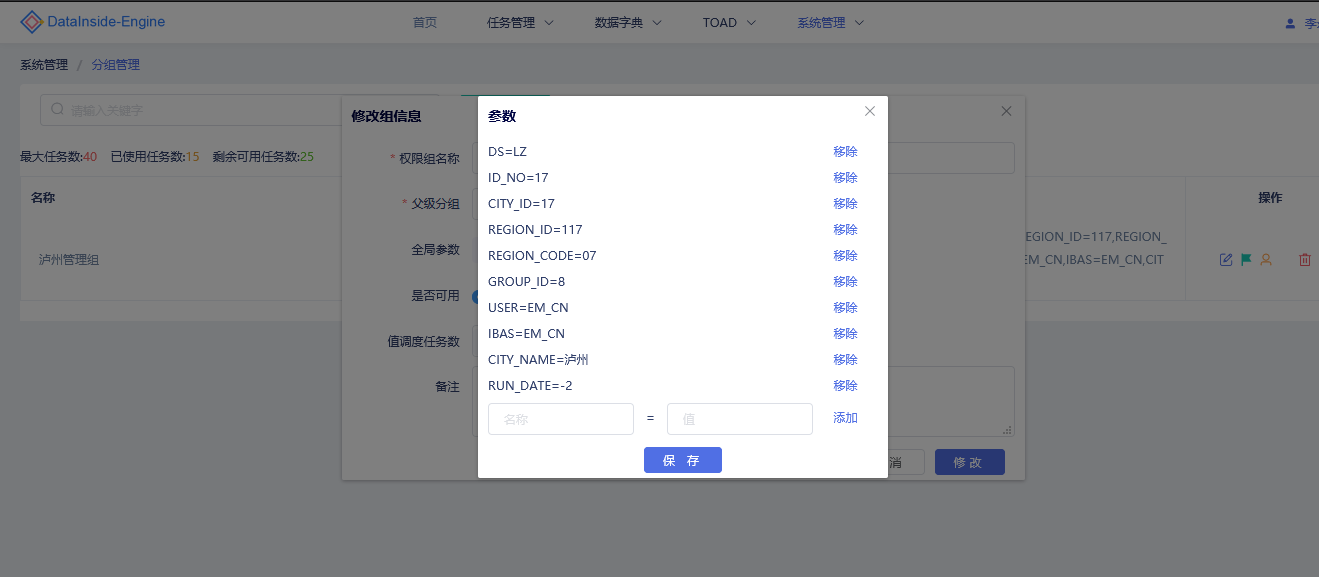
全局自定义参数
全局参数可自定义整个DataInside Engine脚本管理的的动态参数,对所有脚本生效,脚本运行的时候调用全局参数。
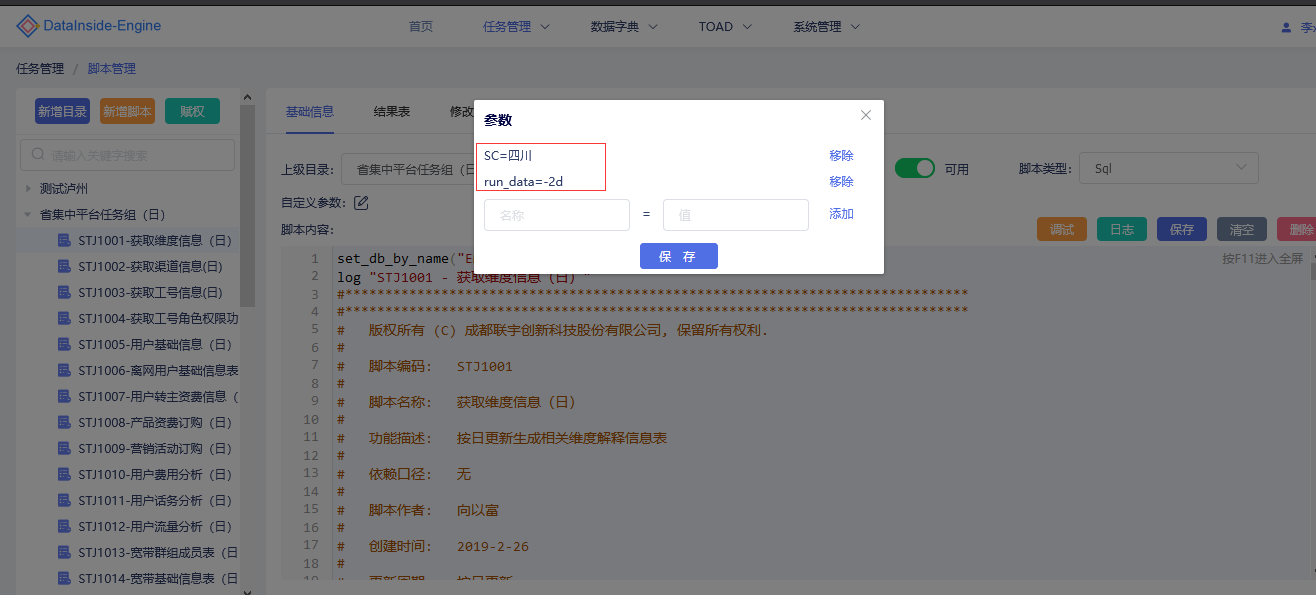
脚本自定义参数
单脚本参数可自定义当前脚本的运行所需动态参数,只对当前脚本生效。
# 4、脚本管理
脚本备份与恢复
划分专用空间,一键备份存储需要备份的脚本,如原脚本意外损坏或丢失后,可用备份脚本快速恢复原脚本。
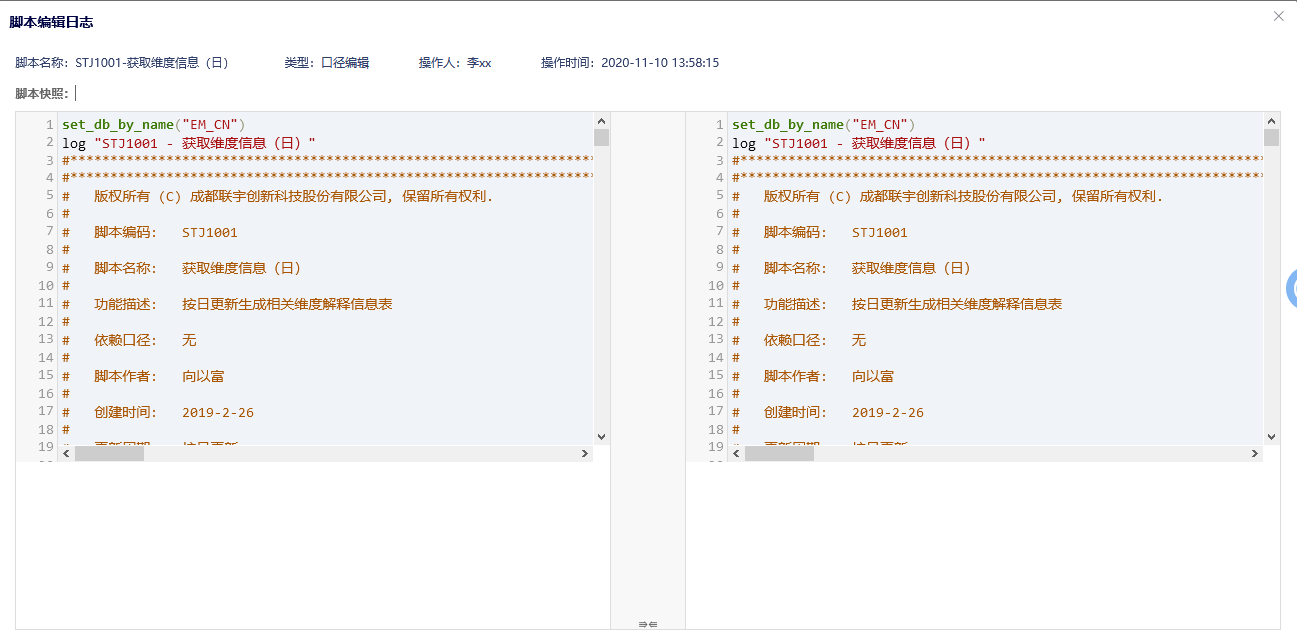
脚本版本管理
对脚本的修改编辑提供历史版本保存管理,记率详细的历史版本信息,包括脚本前后版本对比内容、版本号、修改内容标注、操作人员、操作日期、操作类别,可快速详细的回溯脚本历史版本。
脚本赋权与停用
脚本赋权:当前用户组的脚本可赋权给其他用户组,被赋权的用户组在一定时间段拥有该脚本的使用权,可执行可调度。
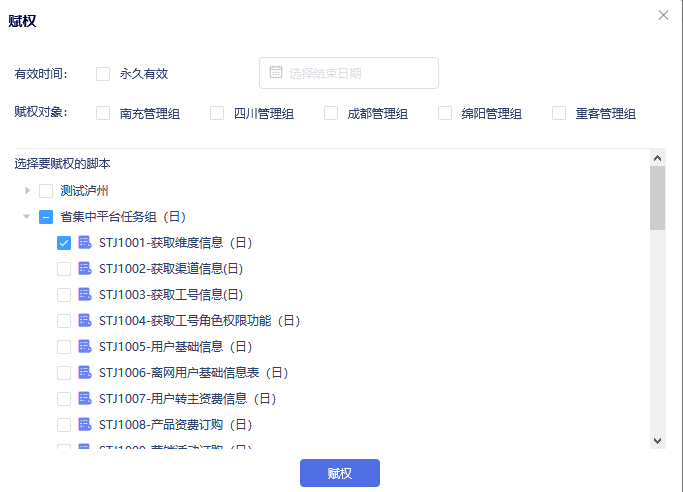
脚本停用:对于已经过期或者不再使用的脚本可执行停用操作,被停用的脚本不再调度运行,禁用后的脚本也可随时恢复。
公共目录
针对多个用户组有相同的需求,可发布一套公用的脚本目录,各用户组配合自定义参数,可同时使用调用运行公共脚本,达到一套脚本多组使用,规范统一脚本规则,减少重复脚本编写工作量。
个人目录
用户创建自己的个性化脚本目录,只供个人或当前用户组使用。
# 5、支持数据平台
支持多种数据库平台,传统关系型数据库:DB2、Oracle、Mysql、SQL Server。
新型大数据平台:Gbase。
其它数据文件:Excel、Txt、Csv。

# 6、Web Toad功能集成
Web Toad是一款无须单独安装轻量级专业的WEB数据库开发工具。支持:代码高亮、自动补全、自动格式化、多标签运行、历史执行SQL记录、SQL收藏,让数据加工人员在进行SQL开发时,更为简便、迅速,大幅提升数据加工人员工作效率,同时有效减低数据库管理员的工作负荷。

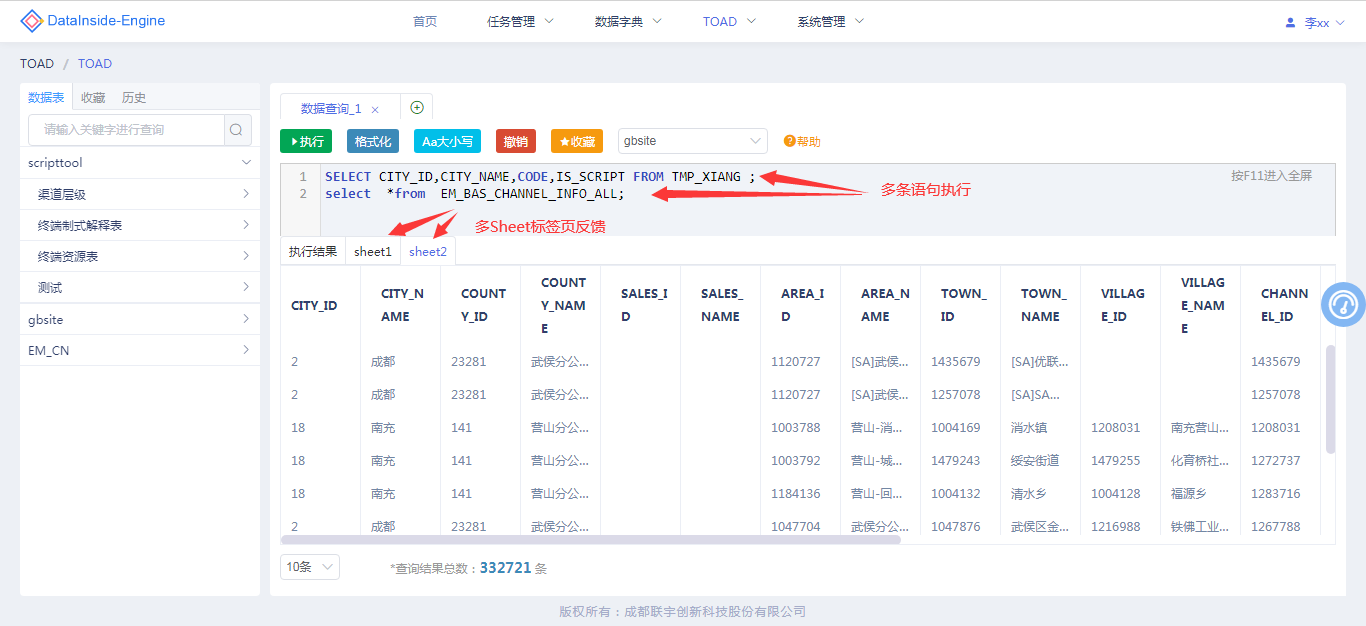
方便临时提数/数据验证
Web Toad方便快速SQL语句的在线调试,支持多条语句同时执行,并对执行结果以Sheet页分别反馈展示,方便工作人员快速对执行结果数据核实验证。
支持数据/表结构/索引/建表语句查询
对已生成数据字典进行常用SQL语句动态生成:数据查询语句、表字段查询语句、表索引查询语句、建表语句,形成功能入口,通过鼠标点击不同功能便能快速将SQL语句发送到Web Toad中执行得到结果。

可支持DDL语句执行
原生支持DDL语句:CREATE TABLE、ALTER TABLE、ALTER COLUMN、DROP TABLE

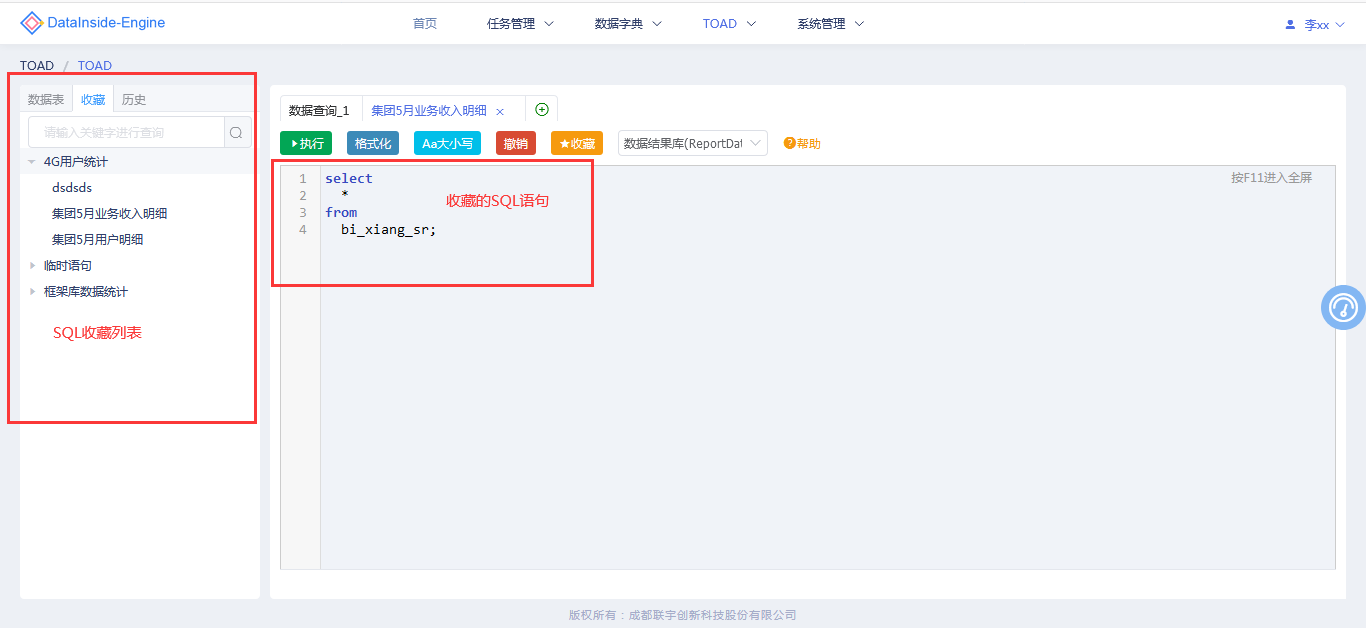
脚本收藏
对常用SQL语句进行分类收藏,通过点击收藏列表能快速将已收藏SQL语句发送到网页TOAD以新的标签页展示,减少重复编写SQL代码。
脚本执行记录
记录TOAD中每次执行的SQL语句,并记录执行状态(成功、失败),可以对历史记录重试。
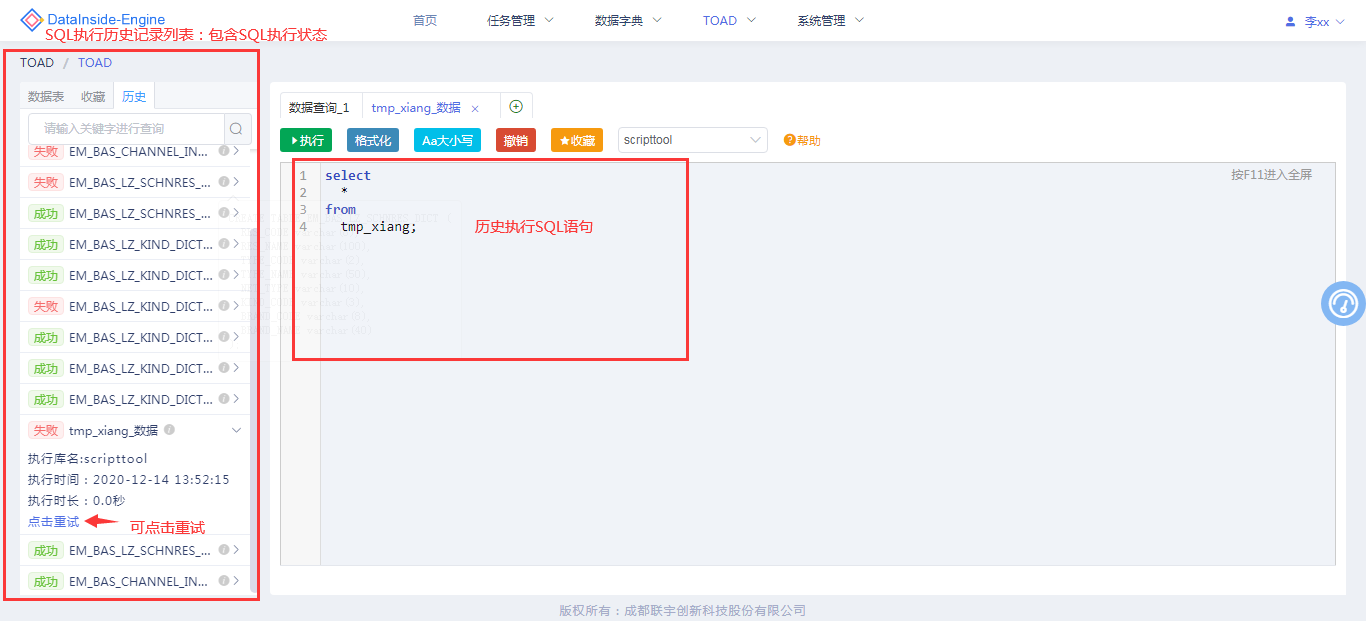
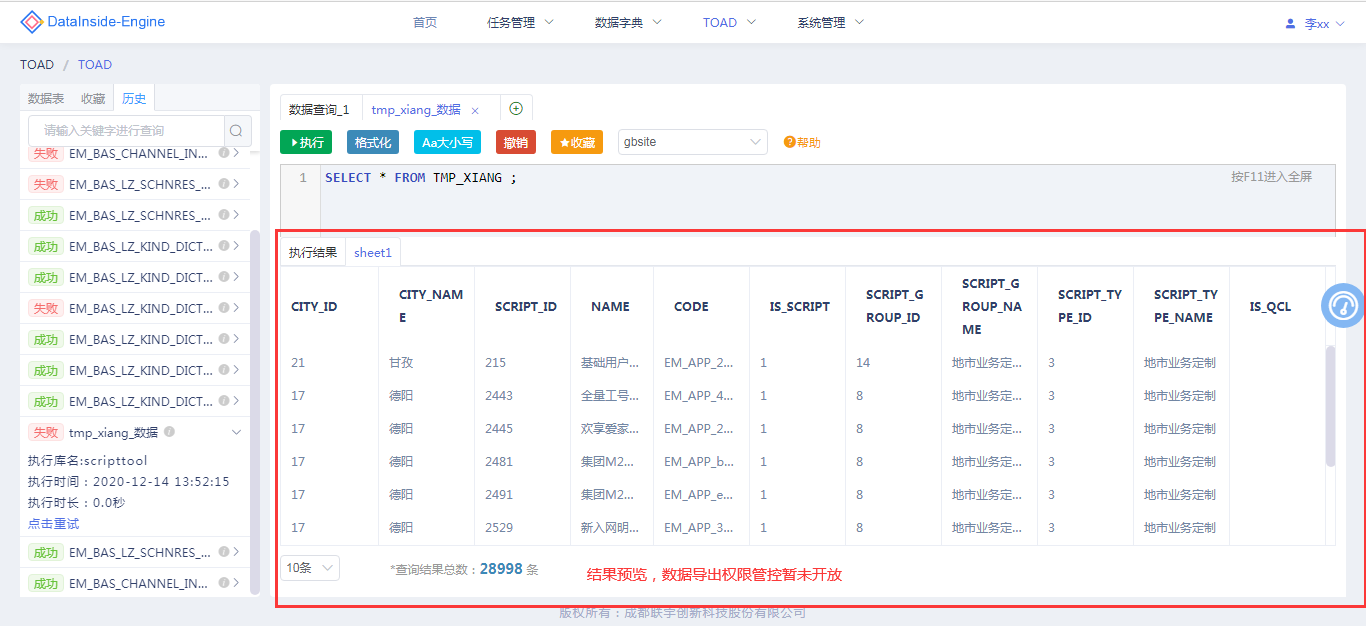
查询结果预览/数据导出
SQL执行结束通过友好的页面展示查询结果,支持多条语句执行结果以Sheet页方式分别展示,方便用户在同一窗口中对多个结果预览并导出。
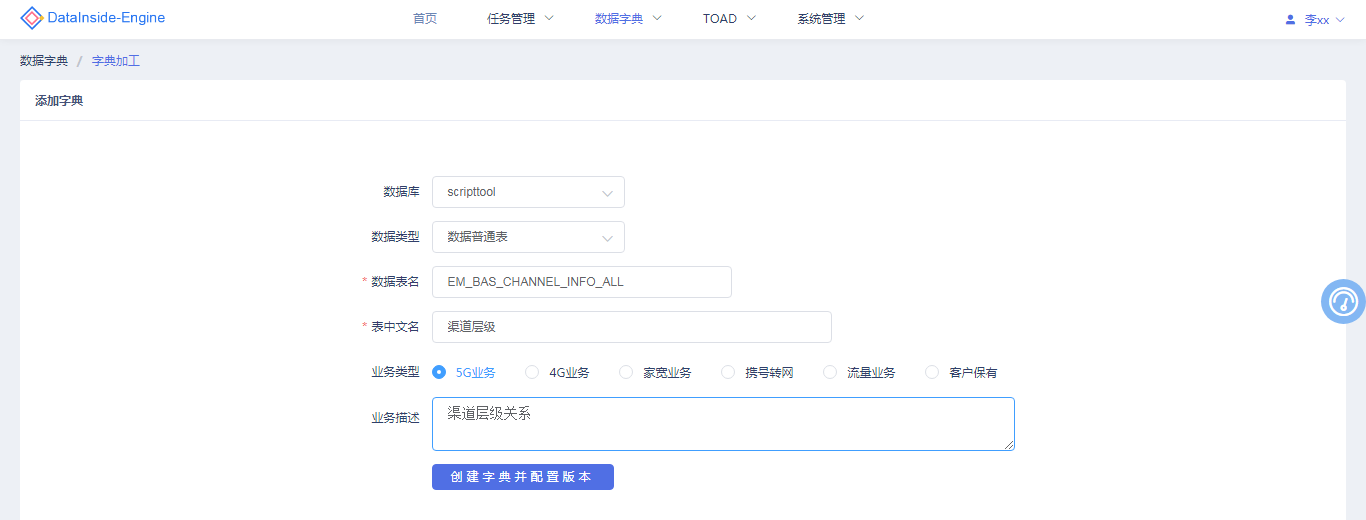
# 7、数据字典
数据字典是描述数据的信息集合,包含对数据字段的新增,修改,删除,中文描述,版本管理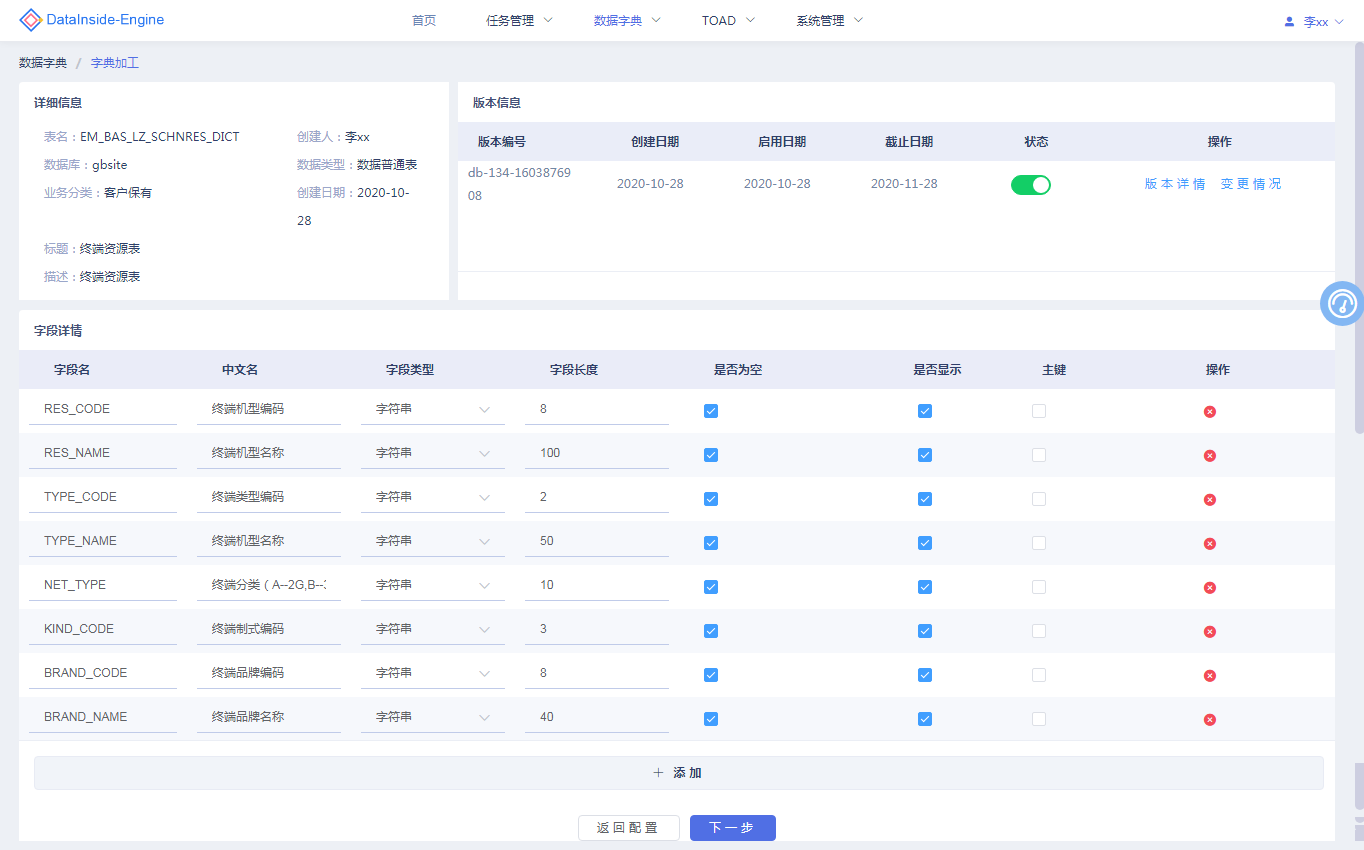
新增结果表数据字典
对执行脚本中产生的结果表进行数据字典创建,通过结果表名称自动获取表中所有字段,进行:添加字段中文描述,修改字段类型,字段长度,是否为空,是否显示,主键,删除字段操作。
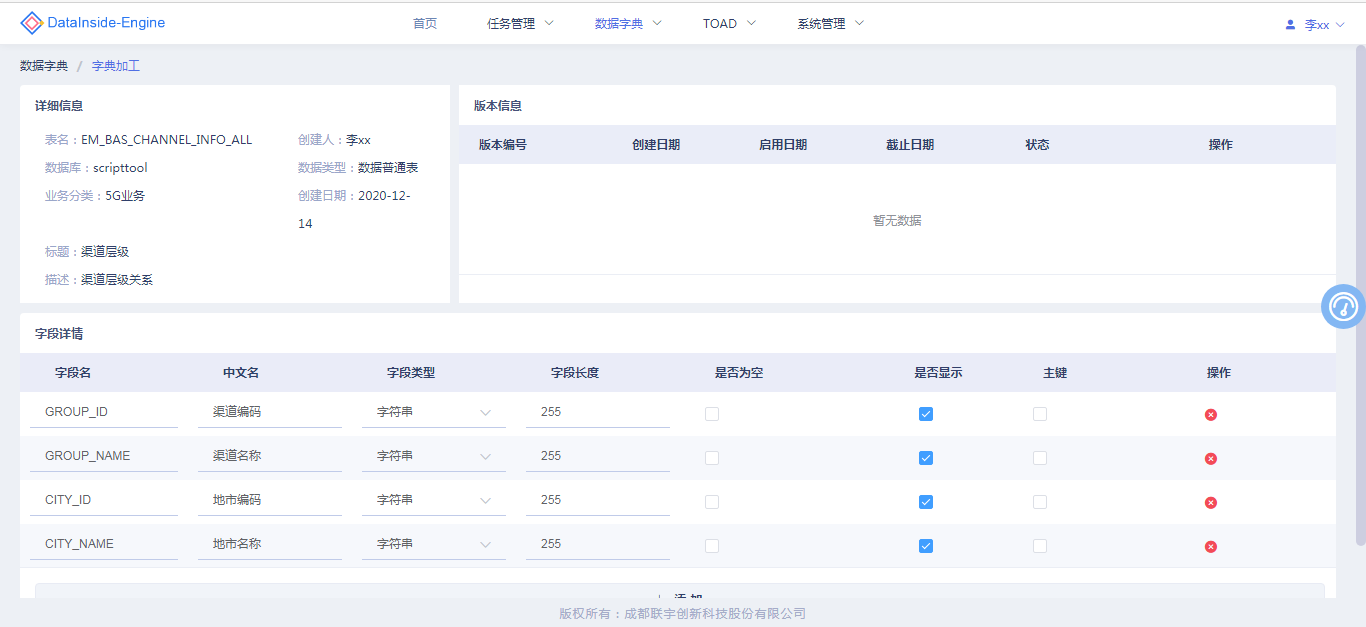
数据字典列表
以列表方式一览实体模型基础信息:表名称、中文名称、数据库、表类型、创建人、版本数量、创建时间、可操作功能(编辑:模型信息编辑、版本信息查看、删除模型、上传模型)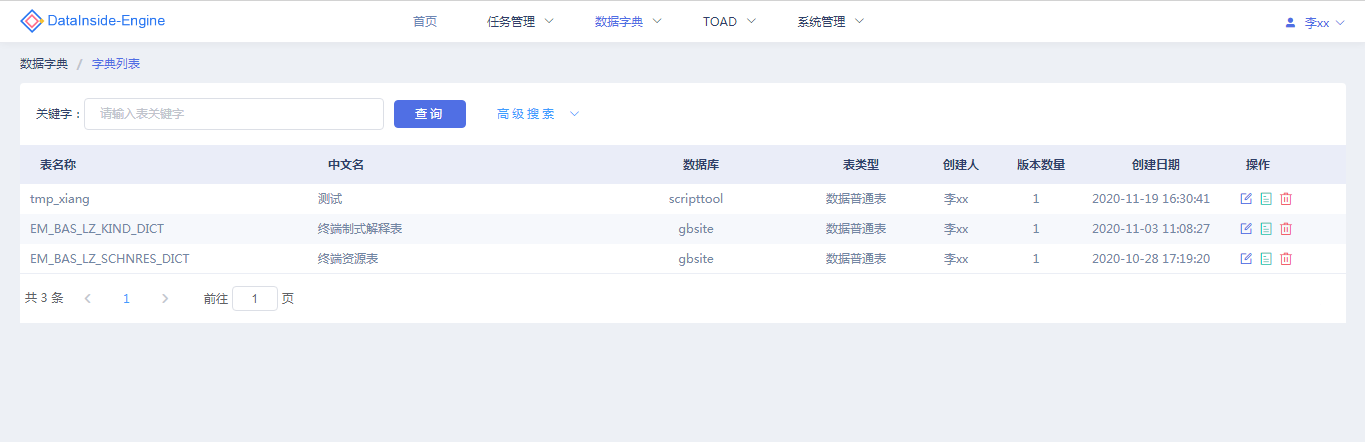
数据字典版本管理
为适配报表在不同时间段展示不同的字段信息,数据字典会根据不同时间段生成不同的数据字典版本。
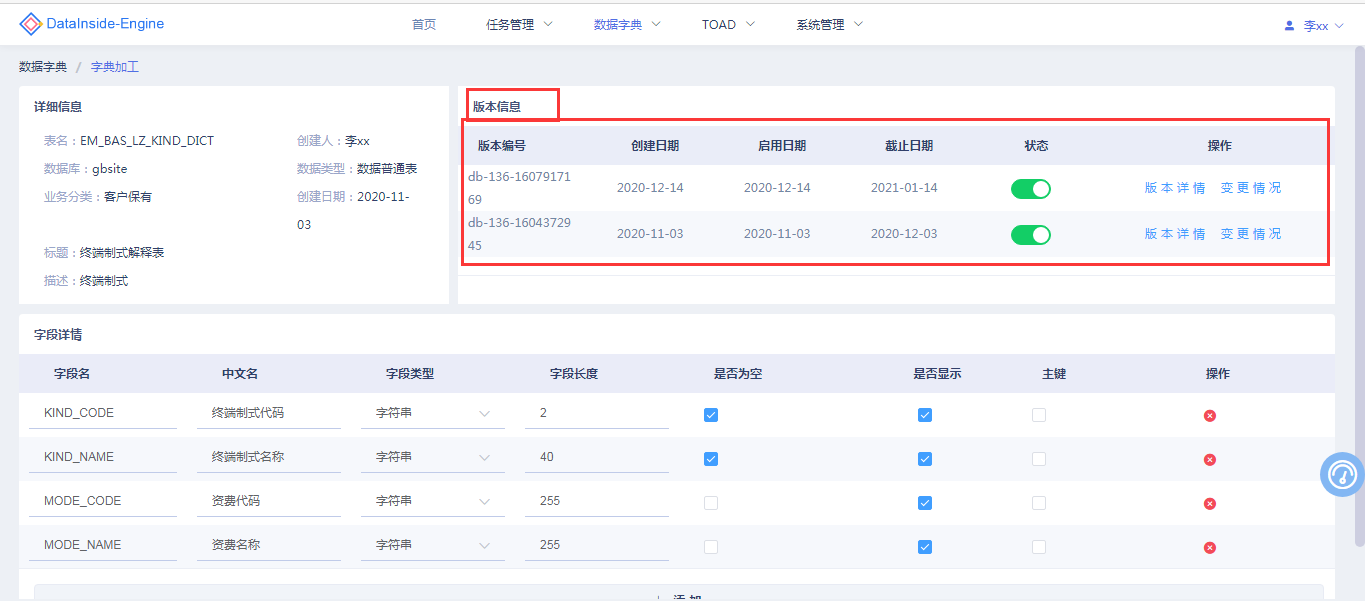
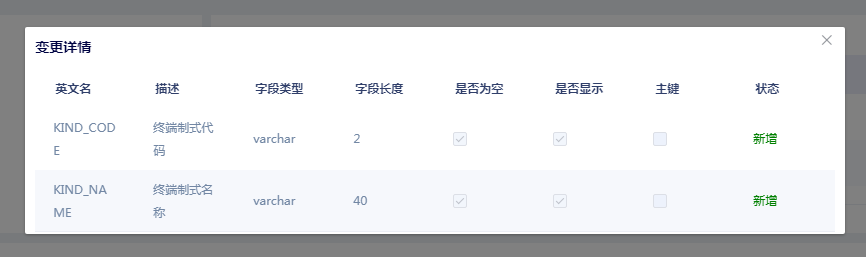
# 8、管理流程规范
脚本编写规范
开始部分
口径开始部分已注明口径的相关信息,具体包括口径编码、口径名称、口径功能、口径实现时间、编写人。变更口径内容是,必须注明变更人、变更时间、变更信息。口径编码必须大写。
中间过程
1)临时表
取数据过程中只能用临时表,不能使用结果表。只能在口径末尾更新结果表,防止在口径执行过程中,结果表的数据重复变化。
2)动态逻辑
确保口径不出现常量,必须通过设定变量并进行赋值来实现,以避免程序写死导致出错或调整编码的大量改动。
3)代码排版
以 Tab为一缩进层次,各个层次之间必须缩进,保证口径排版清晰。
4)大小写规范
关键词大写,如SELECT、FROM 、WHERE 、GROUP BY 、ORDER BY 等。
5)业务注释
1 每一段sql都必须有简洁明了的业务注解。
2 每个表字段必须要求有注释。
6)索引
每个结果表的关键字段都应该有索引,提高模块查询数据的速度。
结束部分
在口径结束部分,必须把当前口径的临时表全部删除。
参数使用说明书
1、参数说明
参数名:参数名可根据使用习惯自定义。如:CITY_NAME
参数值:参数值是传给参数名对应的值。如:CITY_NAME=’成都市’
参数设置:如图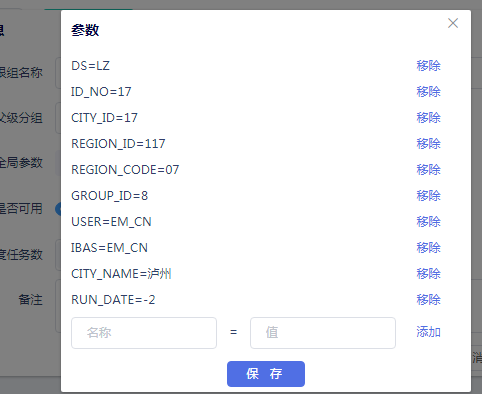
参数使用
格式:@{参数名}
示例:
参数定义:CITY_NAME=’成都市’,USER_NAME=’张三’
参数调用:SELECT @{CITY_NAME} CITYNAME,@{USER_NAME} USERNAME FROM SYSIBM.DUAL
结果:
| CITYNAME | USERNAME |
|---|---|
| 成都市 | 张三 |
表命名规范
1、首字母小写,驼峰命名(小驼峰命名)。
2、禁止混搭拼音与中文,名字尽量要长,需要清晰的描述业务(例如:xiangYiFu)。
代码注释说明
1、单行注释:以#符号进行注释。
2、多行注释:用三引号包含注释内容,可以是三对单引号,也可以是三对双引号。
示例:

日志输出要求
对每一段DDL,DML进行日志输出,包含:执行结果,执行内容,执行时间,执行参数。
# 二、任务管理与调度
可视化任务定义及分布式任务调度包含如下功能:
# 1、可视化任务定义
以更直观的拖拽,连线方式对脚本调度顺序(串行,并行)关系进行设置,以及任务名称、任务参数,执行周期设置。
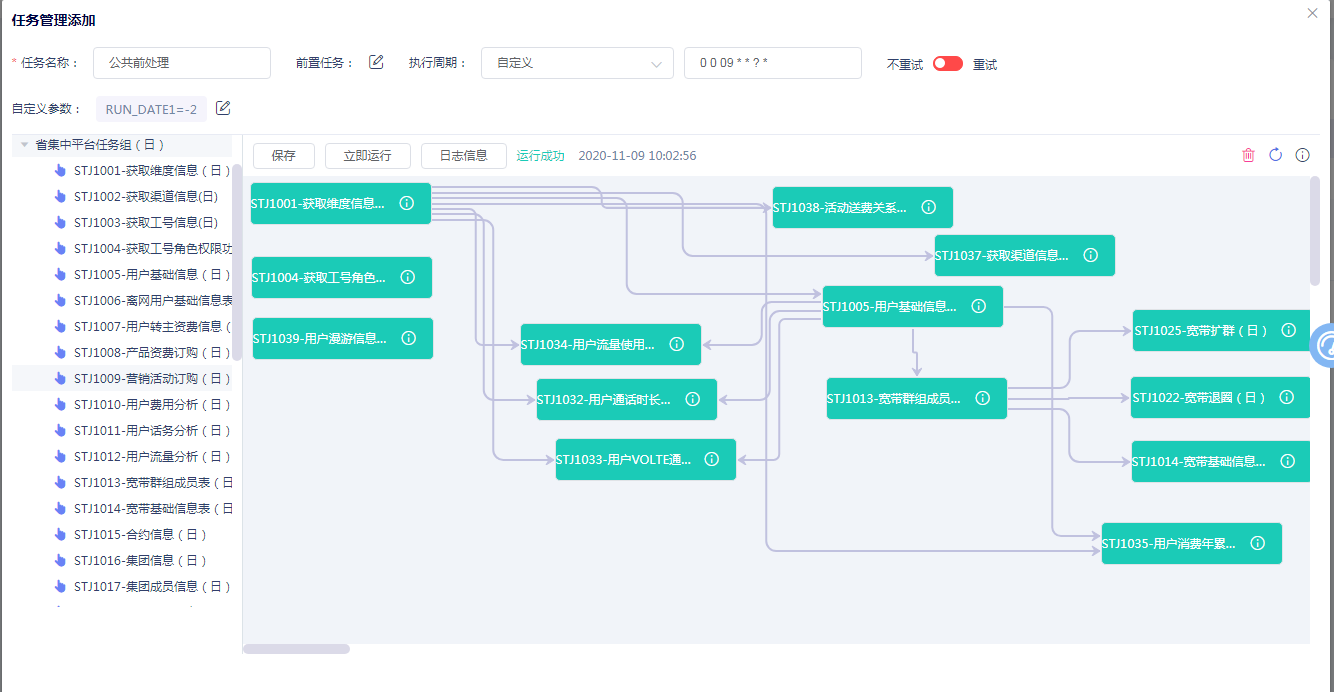
拖拽式构建脚本调度关系
以更直观的拖拽,连线方式对脚本调度顺序(串行,并行)关系进行设置。
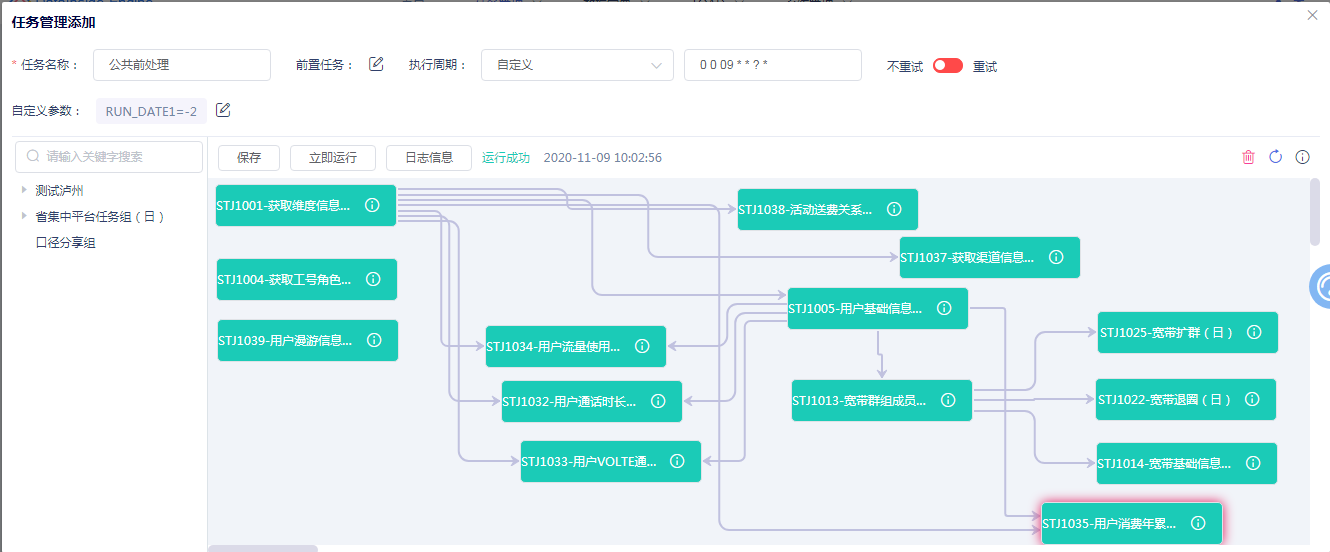
支持脚本并行及串行调度
支持用户在任务中对脚本执行顺序优先级及依赖关系设置,支持同一任务中脚本可并行或串行执行。最大限度利用资源。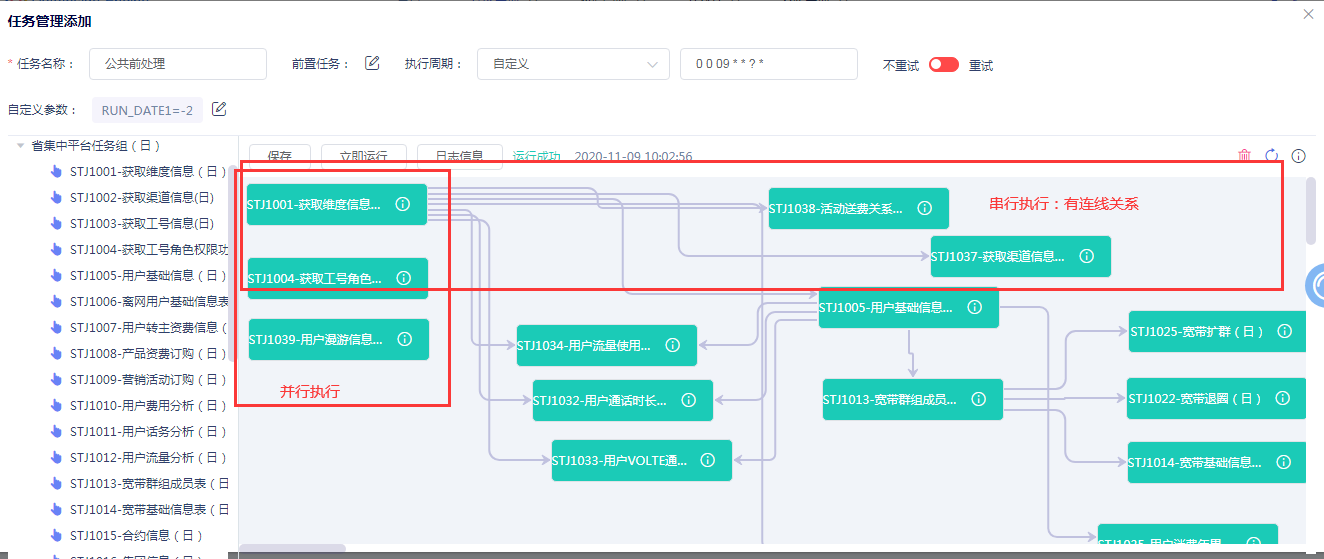
任务参数自定义
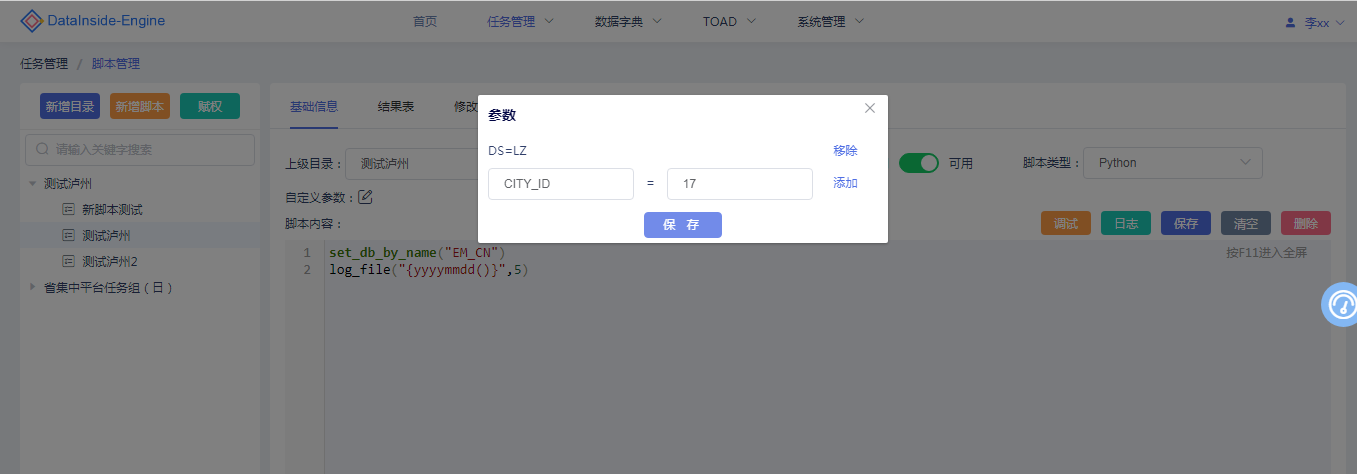
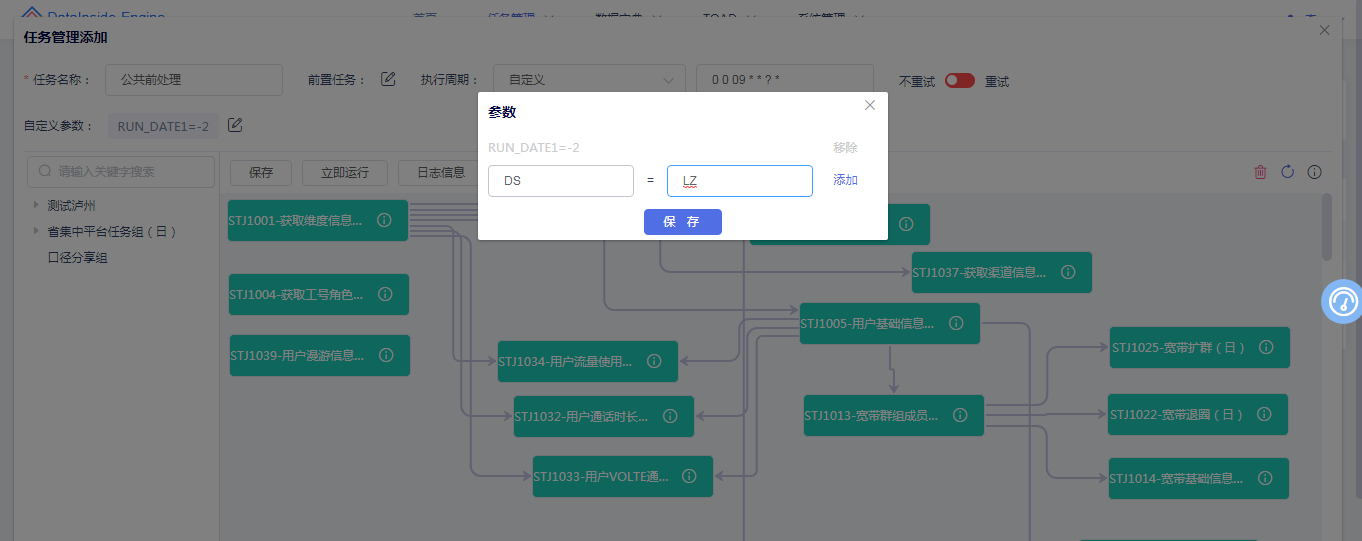
把脚本中常用变量定义为参数,将参数值显现化,通过对参数的自定义,增加脚本复用性。DataInside Engine任务参数分为三种类型:全局参数、脚本参数、任务参数的定义。
1、全局参数:对所有脚本有效。
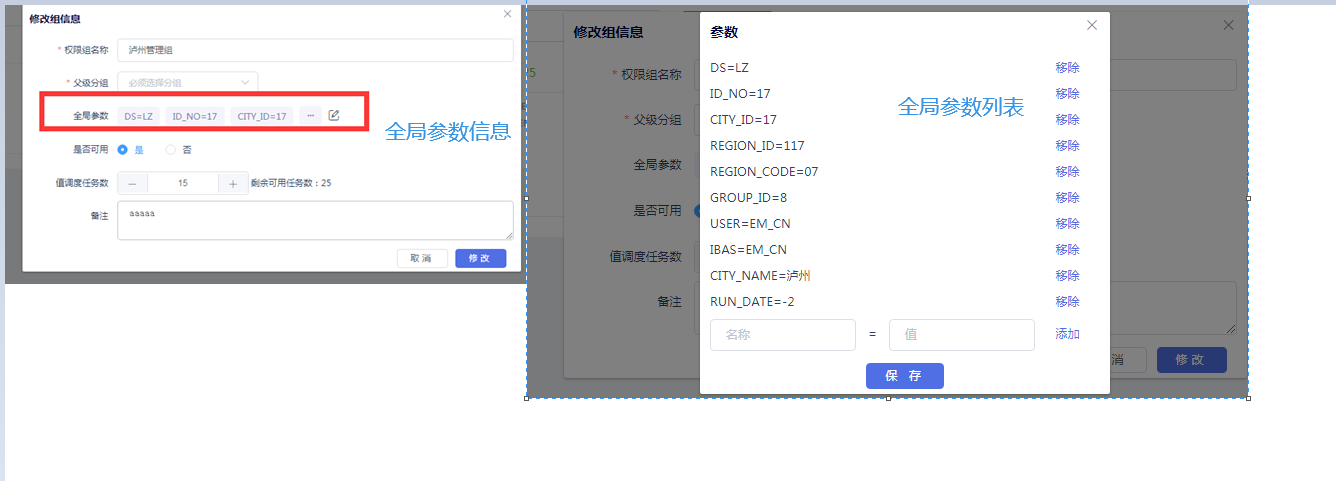
2、脚本参数:只对设置的脚本有效。
3、任务参数:只对该任务中被调度的脚本有效。
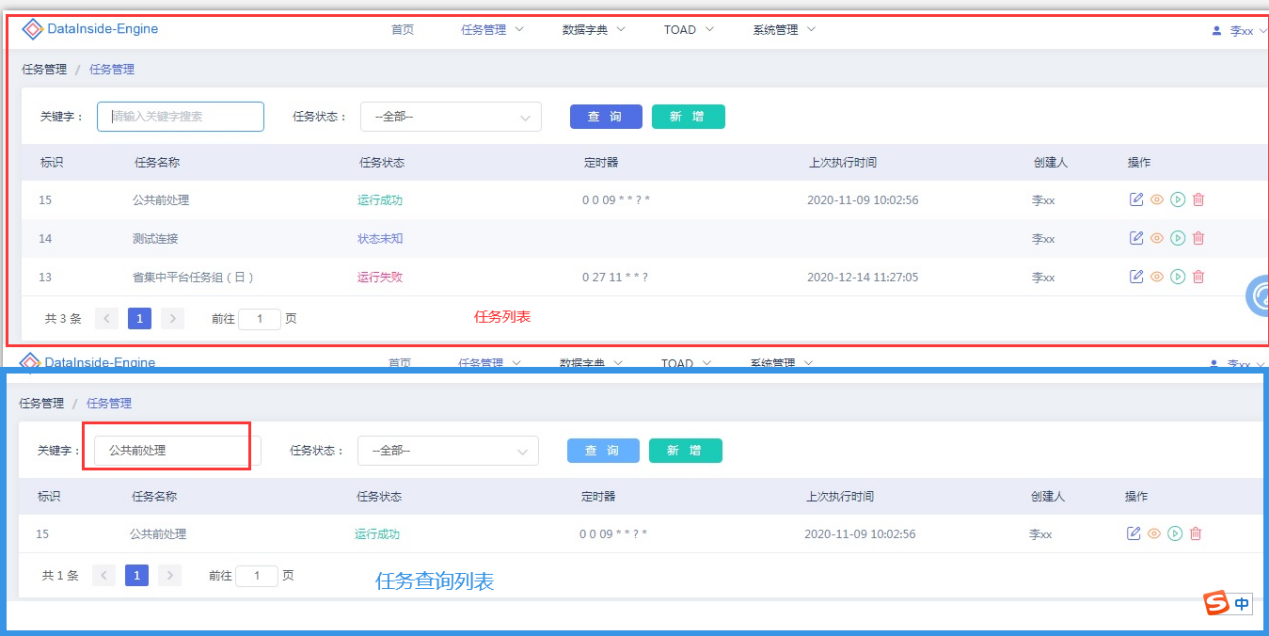
任务查询功能
在任务到达一定数量时,通过一条一条记录挨个查找费时费力,通过任务查询输入关键字或通过任务状态筛选能快速找到需要的任务进行操作。
# 2、任务调度时序管理
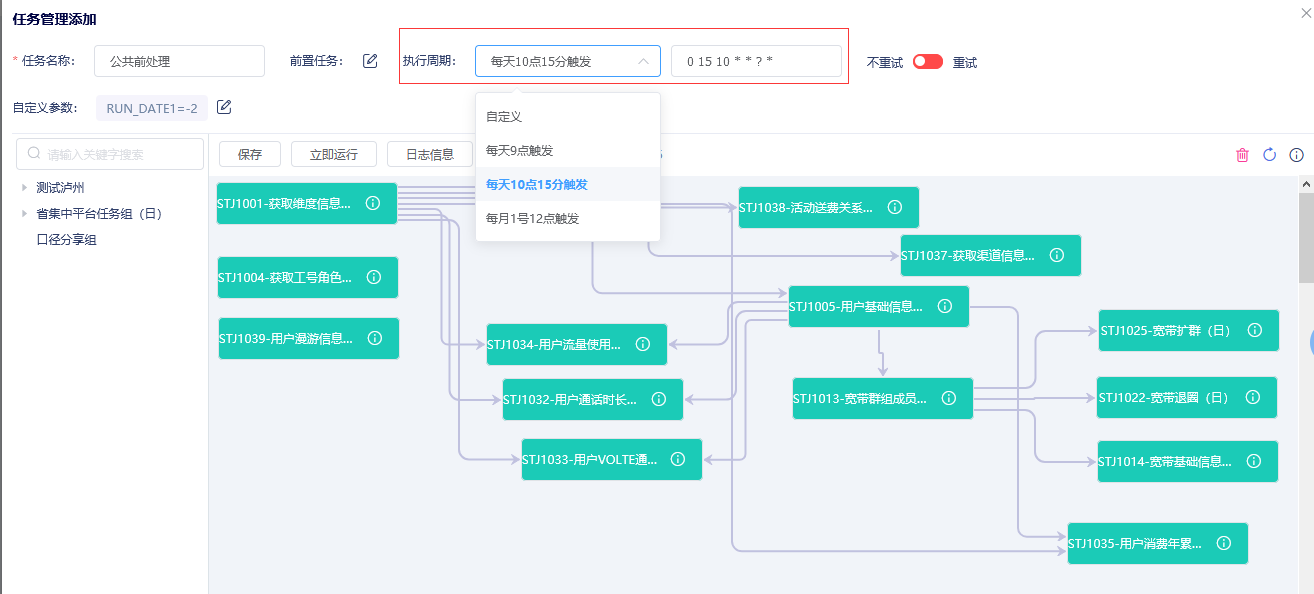
执行周期自定义
用户根据不同任务的情况,可设置任务不同的执行周期,任务的运行通过执行周期定时调度,如每天几点执行,每月哪天执行。
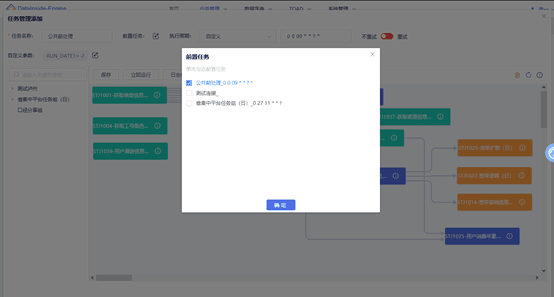
任务依赖关系配置
任务之间可配置依赖关系,各任务按依赖关系时序调度执行,如设置任务为前置任务,则该任务作为最优先运行,其它任务组需该任务组运行完后再依次运行,后续也可配置其它依赖关系。
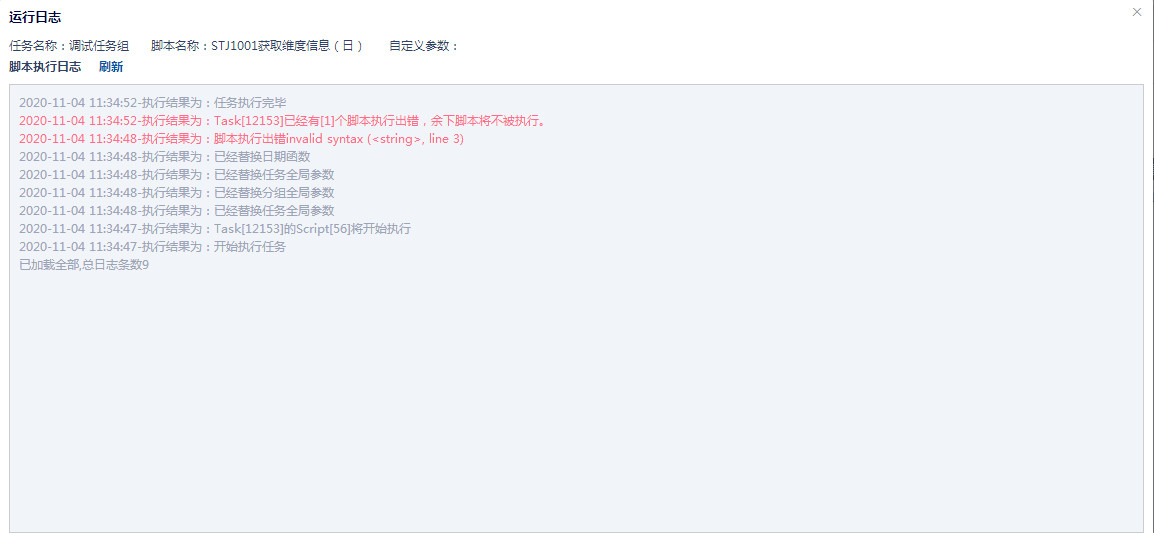
# 3、任务日志管理
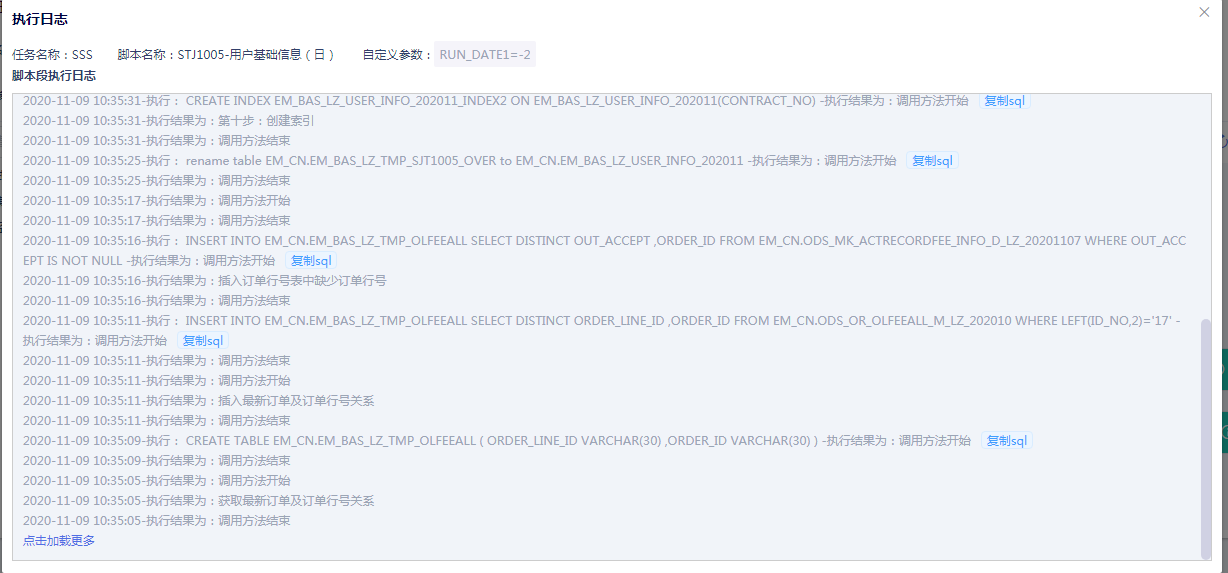
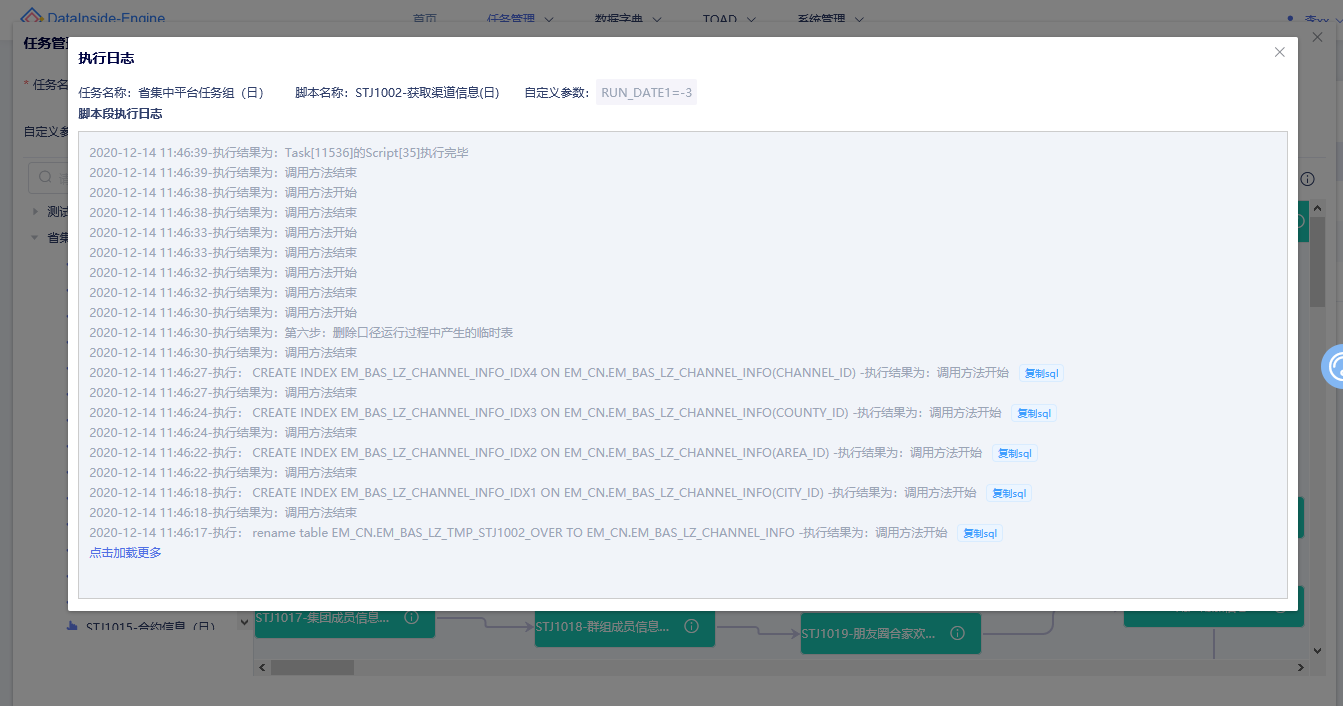
完整的任务运行日志
任务调度执行过程中,记录每一个任务中脚本运行的详细日志,包括任务名称、脚本名称、执行时间、参数、执行语句、执行结果,并可查看当前任务全局日志或单脚本日志,全方位监控任务调度的执行情况。
图一:全局日志

图二:任务中单脚本日志
脚本翻译与执行结果
脚本翻译把脚本中动态的脚本语法,脚本参数,脚本函数,通过脚本翻译功能可翻译为完整脚本执行语句,能清晰明了的查看参数或函数调用是否准确;
可视化的任务执行结果显示,任务调度脚本的执行结果通过脚本图标颜色区分,一目了然的了解任务调度情况,绿色成功,红色失败,橙色等待,蓝色运行。
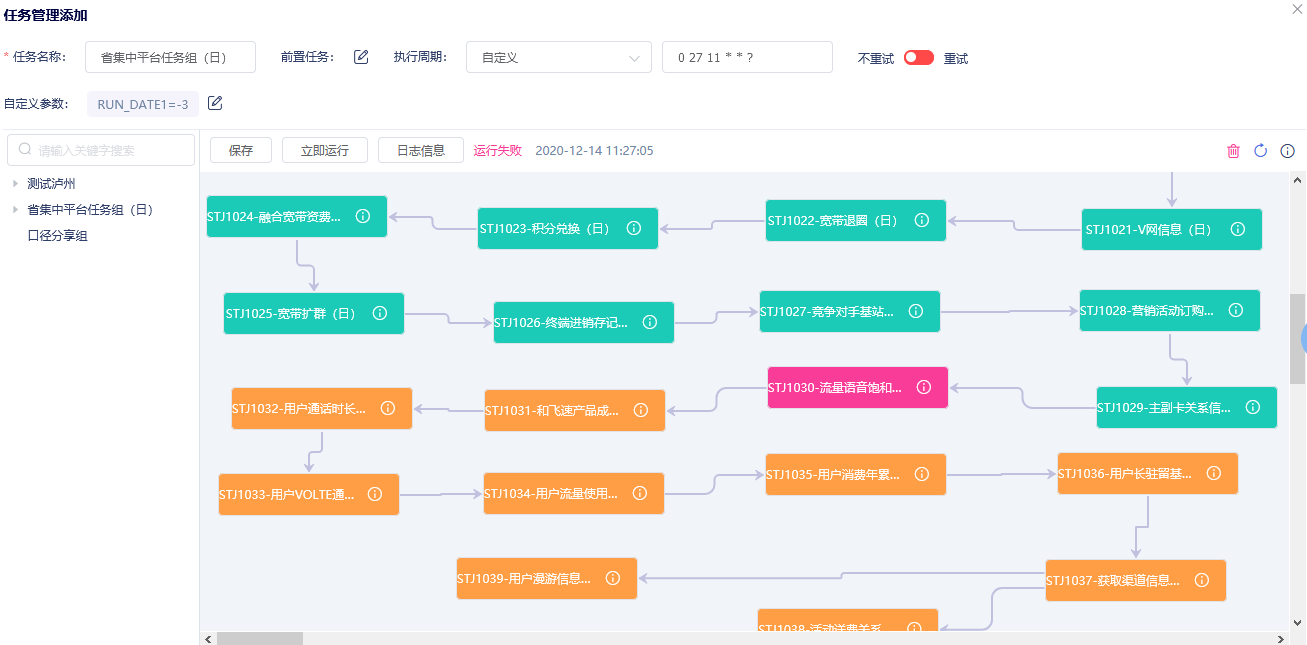
# 4、任务调度机制
支持用户对调度的关系进行可视化查看,从数据的源端到中间处理过程、到数据应用端进行全流程的可视化查看。
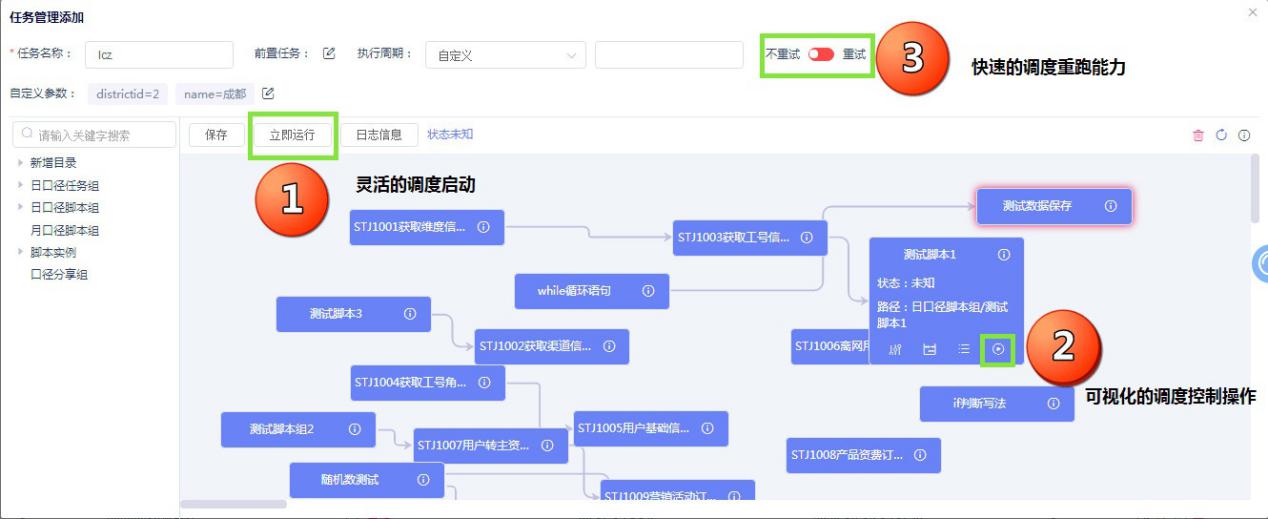
- 灵活的调度启动
根据不同场景的需求,DataInside Engine支持用户选择实时调度、定时调度、周期调度的方式启动数据调度。
- 高效的调度并发机制
提供并发数设置功能,可针对于不同的调度周期或队列,设置不同的并发数。
- 快速的调度重跑能力
当数据出现问题时,DataInside Engine支持快速的调度重跑能力。
- 可视化的调度控制操作
支持对调度的单个节点挂起、中断、重跑等操作。
# 5、调度监控视图
DataInside Engine提供了系统运行的各种统计数据,包括任务统计,字典统计,API统计和脚本动态,全方位的监控系统的日常运作情况。
DashBoard监控驾驶舱

调度状态监控
错误日志监控
# 三、数据质量
# 1、代码规范
制订相关代码编写规范:命名规范、注释规范、代码格式等,让复杂的代码编辑规范化简单化。
- 命名规范
1、表命名:首字母小写,驼峰命名(小驼峰命名)。
2、禁止混搭拼音与中文,名字尽量要长,需要清晰的描述业务(例如:userName)。
- 注释规范
1、代码头部:代码名称、作者、编写时间、描述、修改人、修改时间、修改内容。以/开头,/结束。
2、字段注释:每个字段分别简短描述存放的内容
- 格式规范
1、大小写:关键字大写(SELECT , INSERT ,WHERE ,GROUP BY等)。
2、缩进:以 Tab为一缩进层次,各个层次之间必须缩进,保证口径排版清晰。
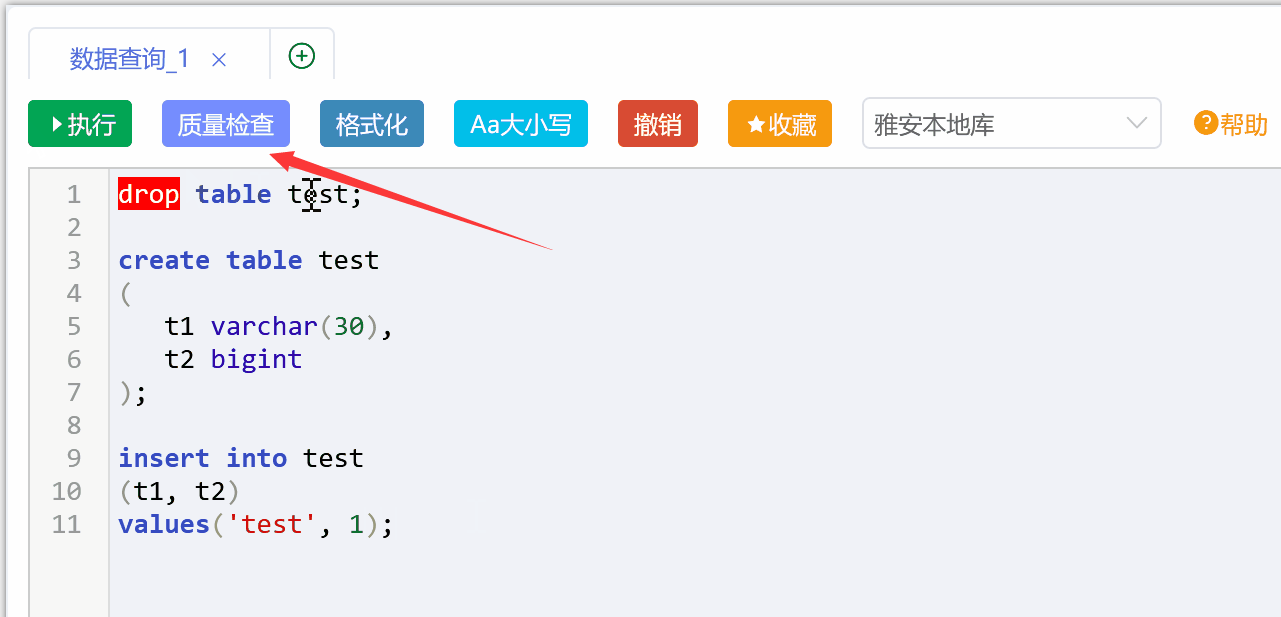
# 2、代码质量检测
对编写完成的代码按照代码规范,代码语法进行检测并提出优化建议,供工程师参考优化代码。降低后续执行过程中产生的故障数,提升代码执行效率。
- 代码规范检测
代码规范检测主要包括:命名规范、格式规范、注释规范。
- 代码语法检测
1、是否有全表扫描语句(NOT IN、NOT LIKE、SELECT *等);
2、是否多表关联(4个及以上表关联);
3、是否有唯一主键、是否有索引
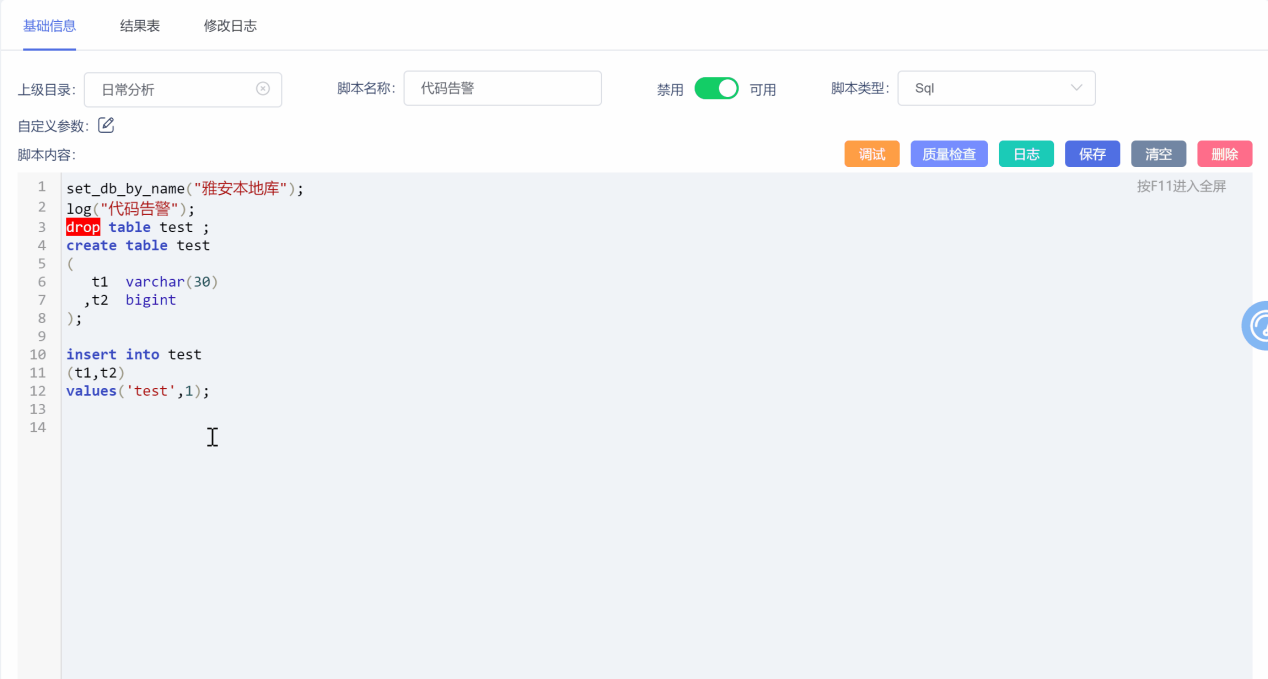
# 3、代码告警
在代码编写过程中对DDL、DML语句按照重大风险、较大风险、一般风险、低风险进行分级监测分别以红、橙、黄、蓝、四种颜色提示。提醒工程师谨慎操作,减少错误操作带来的损失,增强数据的安全性。
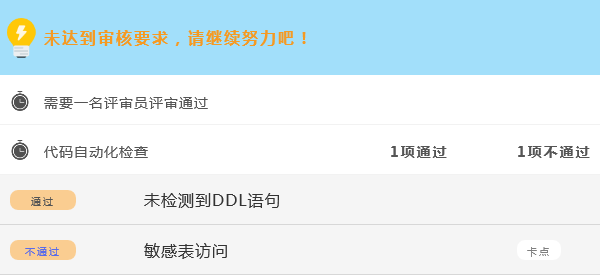
# 4、代码审核
审核人员按照代码规范,代码质量检测优化建议,代码告警等级对代码进行审核确认。通过审核人员对代码的审核,增加了数据的安全性,降低了误操作风险。
# 5、执行后分析
代码执行后效率分析,帮助工程师快速定位到效率低下的代码,给出优化建议,提高代码运行效率,降低数据库负担。
- 效率分析
1、对脚本整体运行时长或脚本分段运行时长超过阈值的进行效率分析。
2、分析内容:找出有全表扫描的语句(select *,not in ,in等)、找出多表关联超过4个以上的语句、Where语句 IN 、NOT IN中包含子查询。
- 优化建议
1、减少SELECT * 全字段查询只查询所需字段降低数据库开销。
2、减少使用 IN ,NOT IN 用EXISTS替代IN、用NOT EXISTS替代NOT IN
3、WHERE 语句IN ,NOT IN内避免使用子查询。
# 四、API接口开放
DataInside Engine提供完整的API文档,用户或第三方可在不依赖平台厂商的情况下,自行开发相关应用,包括应用管控、应用维护、应用展现等;
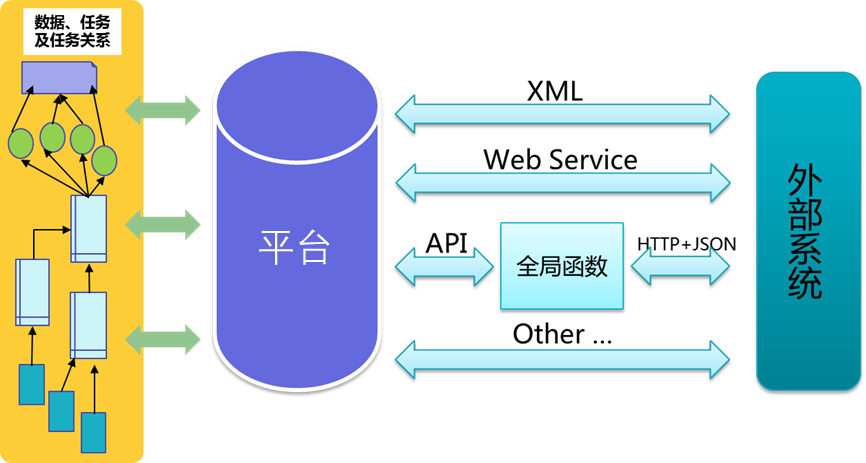
# 1、接口开放
大数据中心的数据统一在一个平台上加工, 其它系统要用就直接调API接口. 对于有众多应用的企业IT环境而言, 这能大幅度提升IT建设的效率, 降低重复开发费用。
# 2、快速响应的标准化流程
要在某个系统中使用数据, 大数据中心接单处理就行, 整个流程得到了大幅度的简化, 同时还可以进行规范化管理. 比如, 某个接口限定了访问频率, 那调用方就不能超过这个频率, 数据库集群的压力就可以统一调度, 避免卡死. 毕竟, 很多系统开发人员不需要具备太多的后台架构知识, 他们的sql水平也参差不齐. 用好API管理这个工具之后, 系统开发人员只需要专注于他的业务逻辑和前端体验, 要数据直接找大数据中心要接口就可以。
# 3、数据资产目录(API接口列表)
DataInside Engine API管理工具, 同时也将大数据中心的数据资产目录化, 并提供了版本管理能力. 系统开发方要使用数据, 可以先到目录中检索一遍, 有就直接使用, 没有再找大数据中心要. 同时, 我们还提供API版本管理的能力, 可以查询该接口的变动历史, 是什么原因要修改这个接口等信息, 这样即便接口变化, 对于使用老版接口的系统开发方来说, 也不会产生任何影响。
# 4、RestFul规范
DataInside Engine的API管理天然就符合RestFul规范, 它本身就具备这样一些特性: 针对实体, 版本信息, 自带增删改查(CRUD), 状态码, 错误信息等。
# 5、API网关权限
API权限管理
①公司或机构注册:注册需要访问接口的公司或机构的信息,并生成访问令牌
②接口权限:为公司或机构分配接口的访问权限,包括接口查询权限、只读、只写权限等;
③访问频率配置:配置接口单日访问次数、访问频率;
④访问列表:配置指定路径来源
⑤接口测试:提供接口测试界面
访问限制:
①接口请求频率,单用户访问频率限制,可配置,默认为500ms;
②接口访问次数:单用户单日访问次数配置,默认为不限制。
③接口访问源设置:配置访问可信IP列表,可配置多个,默认为不限制,
# 五、其它功能
DataInside Engine提供对用户,数据库,主机,权限等分类管理功能
# 1、用户管理
DataInside Engine用户管理通过统一集中的用户管理系统,实现系统的用户、角色和组织机构统一化管理。

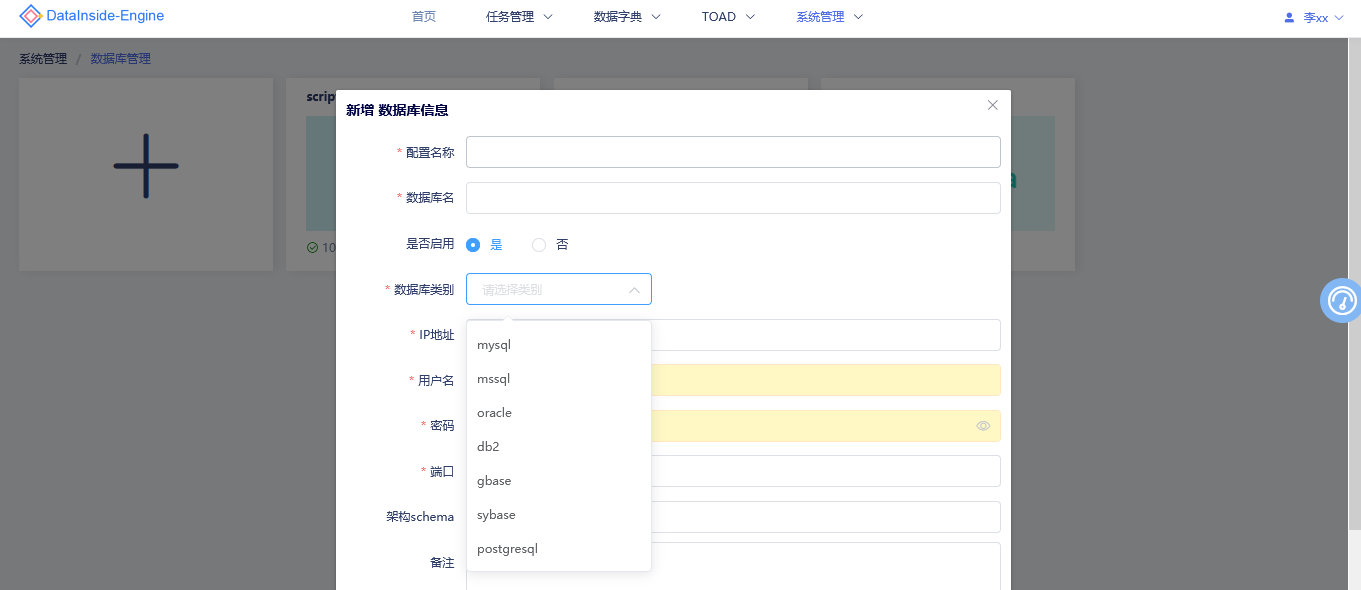
# 2、数据库管理
DataInside Engine可轻松配置对接MySql、DB2、Oracle、GBase等目前主流数据库。
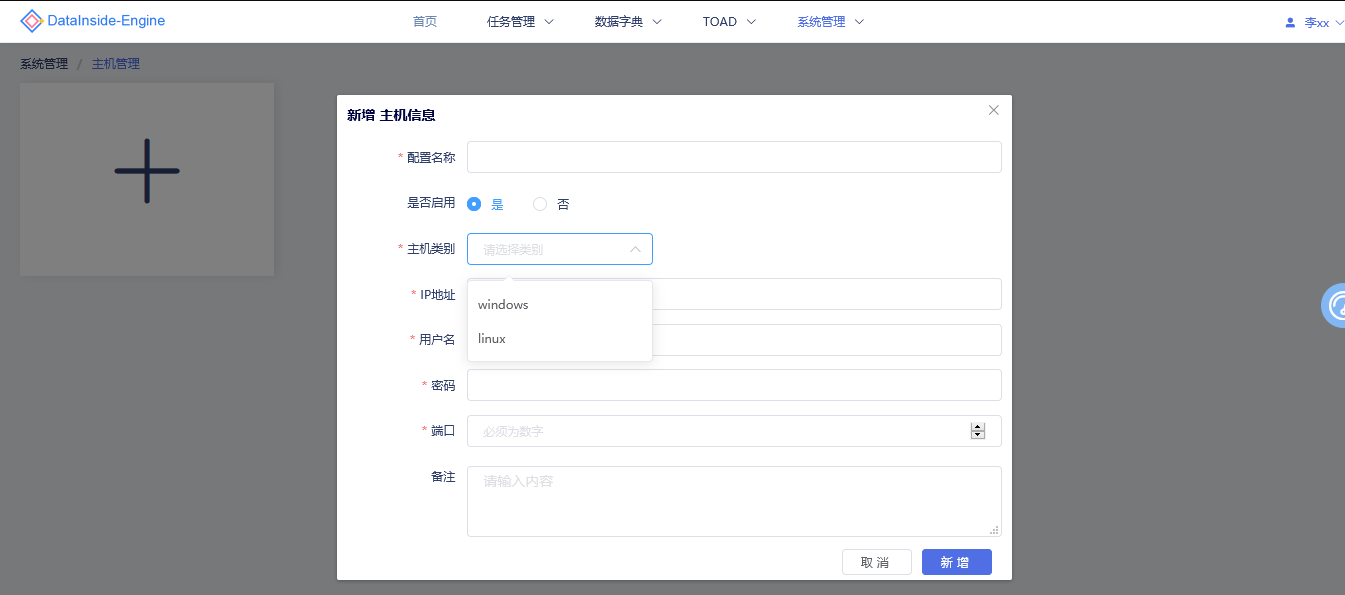
# 3、主机管理
DataInside Engine支持windows及linux系统的主机配置管理。
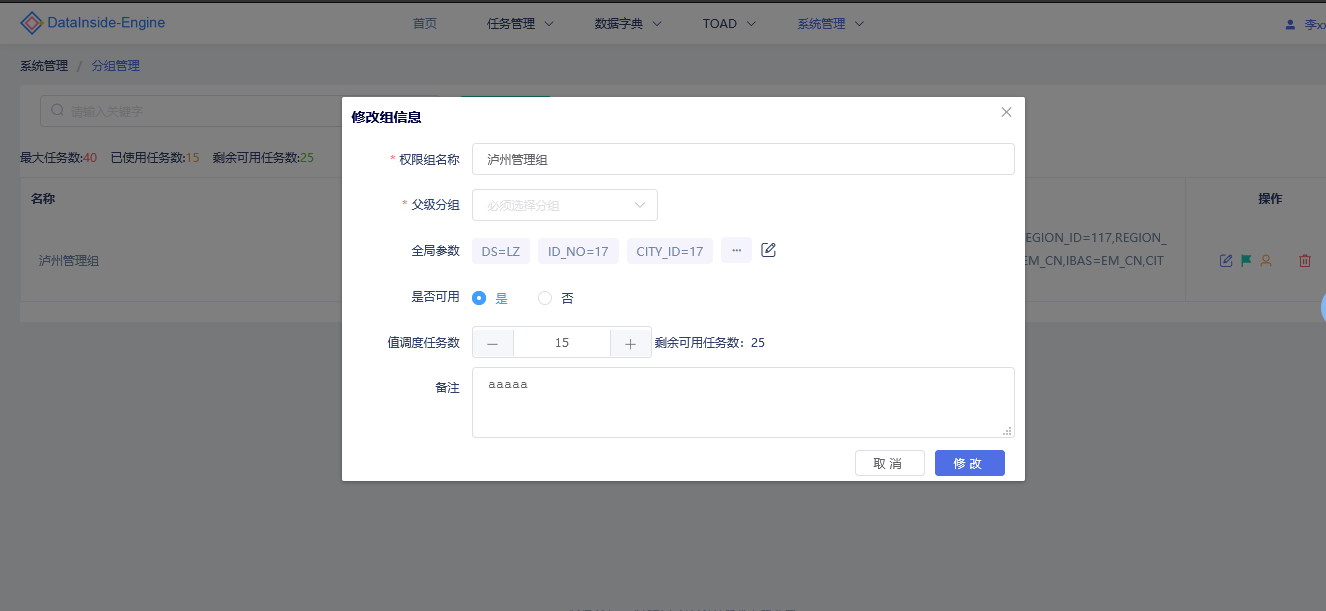
# 3、分组管理
DataInside Engine分组管理提供对权限管理,全局参数,任务数等数据的设置和管理。